9.3. Fortsetzung Selenium#
In der letzten Woche haben wir uns angesehen, wie wir Zitate von der Seite https://quotes.toscrape.com/js/ mithilfe von Selenium scrapen können. Heute werden wir uns ein etwas fortgeschritteneres Beispiel ansehen, bei dem die Interaktion mit verschiedenen Seitenelementen notwendig wird: Wir werden Ortsangaben zu Unterkünften von https://www.airbnb.com/ scrapen, zuerst die Unterkünfte von der Startseite (heute), und danach Unterkünfte nur in Berlin (nächste Woche).
Zunächst rufen wir die Website im regulären Browser auf. Welche Interaktionen sind notwendig, um an die gesuchten Daten zu gelangen? Wenn wir die Startseite aufrufen, erscheint zunächst ein Popup-Fenster. Das Fenster kann geschlossen werden, indem auf den x-Button oder irgendwo neben das Fenster geklickt wird. Dann scrollen wir auf der Seite herunter, um die restlichen Unterkünfte zu sehen. Am Seitenende befindet sich ein “Show more”-Button. Wenn der Button geklickt wird, wird eine weitere Seite mit Unterkünften geöffnet. Die Inhalte werden beim Herunterscrollen nachgeladen, bis irgendwann das Seitenende erreicht ist. All diese Schritte müssen wir simulieren, wenn wir die Ortsangaben von den Unterkünften extrahieren wollen.
Note
Achtung: Beim Scrapen komplexerer Webseiten wird der Code nicht beim ersten Mal fehlerfrei ausgeführt werden. Wird die Ausführung abbricht und eine Fehlermeldung angezeigt, dann wird die aktuelle Sitzung aber nicht mehr geschlossen. Das heißt: Immer, wenn der Code abbricht, müsst ihr die Sitzung manuell mit driver.quit() schließen, und vor dem nächsten Versuch wieder eine neue Sitzung starten mit webdriver.Chrome()!
Zu Beginn laden wir wieder alle notwendigen Pakete, starten eine Sitzung und stellen eine HTTP Get-Anfrage:
# from selenium import webdriver
# from selenium.webdriver.common.by import By
# import time
# driver = webdriver.Chrome()
# driver.get("https://www.airbnb.com/")
# time.sleep(5) # 5 Sekunden warten, damit Inhalte laden können
9.3.1. Popup-Fenster schließen#
Beim manuellen Aufruf der Seite haben wir gesehen, dass das Popup-Fenster mit zwei verschiedenen Methoden geschlossen werden kann: Entweder, es wird auf den x-Button geklickt, oder irgendwo neben das Popup-Fenster. Beides können wir mithilfe von Selenium simulieren.
9.3.1.1. Methode 1: Button klicken#
Zum Simulieren des Mausklicks auf einen Button gibt es wiederum zwei Möglichkeiten. In jedem Fall muss zunächst das HTML-Element, das zur Darstellung des Buttons verwendet wird, gesucht werden.
Um das Element zu suchen, verwenden wir als erstes wieder die Browser-Entwicklertools: Mit Rechtsklick auf den Button und Auswahl von “Inspect” wird der Quelltext der Seite automatisch an der richtigen Stelle in den Entwicklertools geöffnet. Häufig wird nicht exakt das gesuchte Element markiert, sondern ein Kind- oder Elternelement. Das richtige Element heißt <button>:
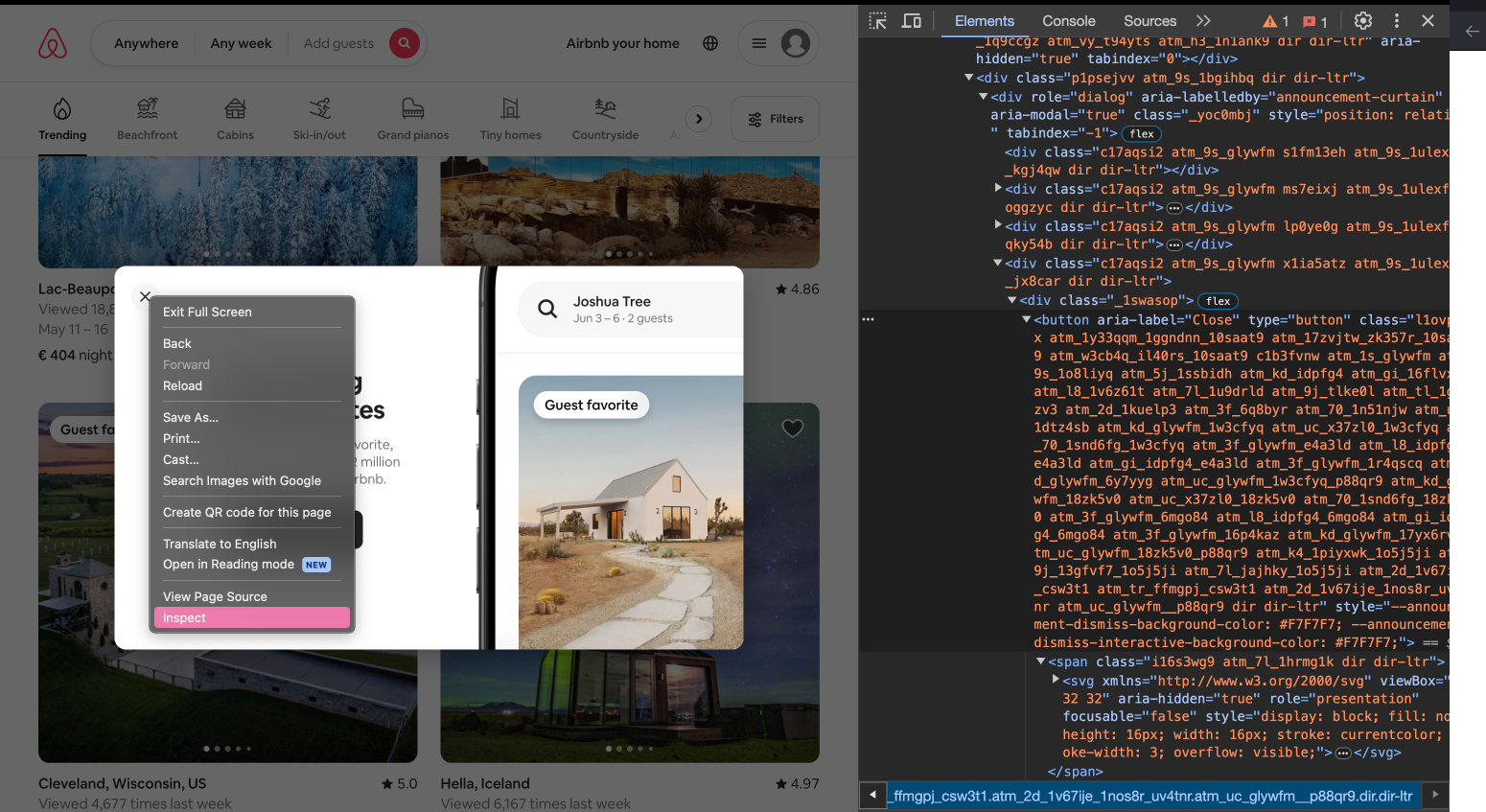
Fig. 9.9 Button-Element mithilfe der Entwicklertools suchen.#
Welches Attribut identifiziert das button-Element eindeutig? Das button-Element hat ein “class”-Attribut, das allerdings eine sehr lange Zeichenkette als Wert hat. Das kann vorkommen, wenn mehrere CSS-Klassen zur Identifizierung eines HTML-Elements verwendet werden. Verschiedene Klassen werden dabei durch ein Leerzeichen getrennt. Das Leerzeichen verursacht aber bei der Suche mit By.CLASS_NAME ein Problem und führt dazu, dass der Code eine Fehlermeldung produziert. Bei einer so langen Zeichenkette wäre das manuelle Ersetzen der Leerzeichen durch Punkte hier jedoch keine gute Lösung.
Stattdessen könnten wir überprüfen, ob das gesuchte Element schon durch die erste CSS-Klasse oder nur einige wenige Klassen eindeutig definiert wird. Das können wir überprüfen, in dem wir in den Entwicklertools mit der Tastenkombination STRG + F nach der ersten CSS-Klasse suchen. Es zeigt sich: Der Close-Button ist nicht der Einzige, der diese CSS-Klasse hat; sondern es gibt sehr viele Elemente mit dieser Klasse:
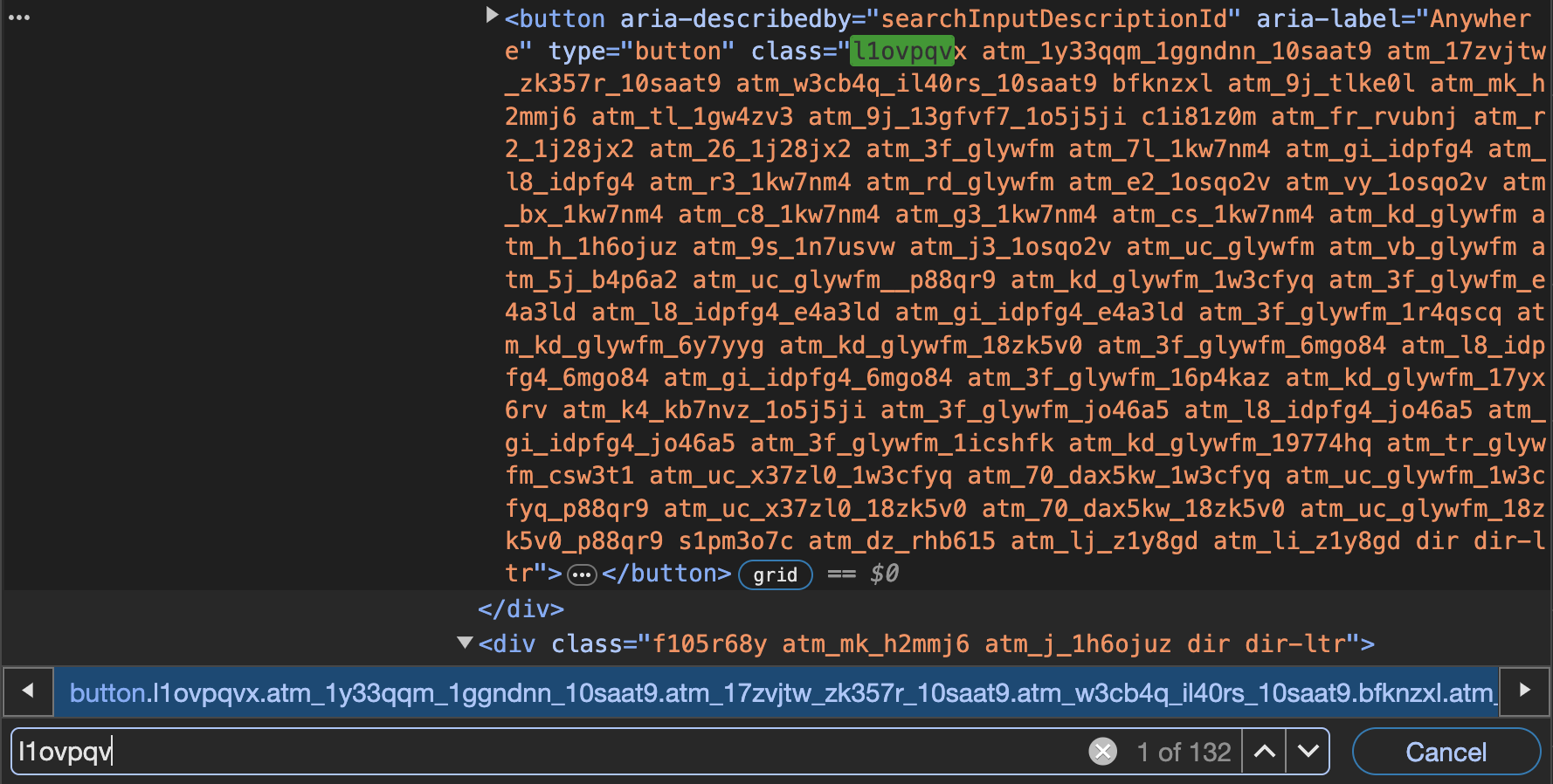
Fig. 9.10 Suche nach CSS-Klasse mit STRG + F.#
Wir können also das Button-Element nicht eindeutig über die gewählte CSS-Klasse addressieren. Wir könnten jetzt natürlich verschiedene Kombinationen von CSS-Klassen ausprobieren, aber das Button-Element hat noch ein weiteres Attribut, über das das Button-Element etwas einfacher addressiert werden kann: Das Attribut aria-label mit dem Wert “Close”. Wir verwenden stattdessen dieses Attribut für die Suche und definieren dazu einen sogenannten XPATH-Ausdruck. XPATH ist eine Pfadbeschreibungssprache, mit der HTML-Elemente anhand ihrer Hierarchie, Attributen, Textinhalten und weiteren Eigenschaften lokalisiert werden können. So können wir zum Beispiel den Button mit dem XPATH-Ausdruck //button[@aria-label='Close'] auswählen. Dieser Ausdruck sucht nach einem Element mit den Namen button (button), irgendwo im HTML-Baum (//), das ein Attribut aria-label mit dem Wert 'Close' hat ([@aria-label='Close']). Einen Überblick über verschiedene Möglichkeiten, in Selenium nach Elementen zu suchen, findet ihr hier.
Anschließend kann der Mausklick mit der Selenium-Methode .click() simuliert werden.
# close_button = driver.find_element(By.XPATH, "//button[@aria-label='Close']")
# close_button.click()
Dieser Code produziert jedoch eine Fehlermeldung “ElementNotInteractable”. Woran liegt das? Wenn wir wieder mit STRG + F das Suchfenster in den Entwicklertools öffnen und nach dem XPATH-Pfad suchen, erhalten wir zwei Ergebnisse, und nicht eins wie erwartet. Die Methode .find_element() gibt aber natürlich nur das erste der beiden Suchergebnisse zurück. Das erste der beiden gefundenen Elemente ist aber scheinbar nicht anklickbar bzw. eben “nicht interagierbar”. Wir können stattdessen versuchen, das andere gefundene Element anzuklicken. Dazu müssen wir aber unsere Suche anders formulieren:
# close_button_elems = driver.find_elements(By.XPATH, "//button[@aria-label='Close']")
# close_button_elems[1].click() # Zweites Element aus der Liste mit den gefundenen Elementen anklciken
Mit dem geänderten Code lässt sich der Mausklick erfolgreich simulieren.
Falls die erste Methode jedoch nicht zum Ziel führt, gibt es eine alternative Möglichkeit, einen Button anzuklicken, und zwar, indem das JavaScript Code Snippet ausgeführt wird, das dafür zuständig ist, den Mausklick im Browser auszulösen. Dazu wird die Selenium-Methode .execute_script() im Zusammenhang mit der Javascript-Methode .click() verwendet. Die JavaScript-Methode heißt ebenfalls .click() und ist genau wie die Selenium-Methode .click() für HTML-Elemente definiert, aber eben für JavaScript und nicht Python. Im Codebeispiel unten steht arguments[0] für das HTML-Element, das angeklickt werden soll. Das Element muss deswegen wieder zuerst gesucht werden und einer Variable zugewiesen werden. Diese Variable (hier close_button) wird der .execute_script()-Methode als Argument übergeben. arguments[0] verweist dann auf das Argument.
# close_button = driver.find_element(By.XPATH, "//button[@aria-label='Close']")
# driver.execute_script("arguments[0].click();", close_button)
# time.sleep(5)
Unter den folgenden Links findet ihr Hintergrundinformationen und Anwendungsbeispiele zur .execute_sript() Methode:
9.3.1.2. Methode 2: Mauszeiger bewegen und neben das Fenster klicken#
Die zweite Möglichkeit, das Fenster zu schließen, besteht darin, irgendwo neben das Fenster zu klicken. Auch das kann mithilfe von Selenium simuliert werden. Dazu muss zunächst ein Element gefunden werden, das eindeutig identifiziert werden kann. In unserem Beispiel ist das z.B. das div-Element mit der Klasse “_17t88vi”, das das Popup-Fenster repräsentiert. Wenn wir nach der Klasse “_17t88vi” suchen, wird nur ein Ergebnis gefunden. Wir können also zunächst den Mauszeiger in die Mitte dieses Elements bewegen, und von dort aus den Mauszeiger um eine festgelegte Pixelanzahl nach oben (y) und nach rechts (x) bewegen, also genau wie in einem Kartesischen Koordinatensystem.
# mouse_tracker = driver.find_element(By.CLASS_NAME, "_17t88vi")
# Koordinaten
# x_coordinate = 450 (etwa 12 cm in Pixeln)
# y_coordinate = 450
# ActionChains(driver).move_by_offset(x_coordinate, y_coordinate).click().perform()
# Mausposition neu ausrichten
# ActionChains(driver).move_by_offset(-x_coordinate, -y_coordinate).perform()
# time.sleep(5)
Hintergrundinformationen und Anwendungsbeispiele zur Methode .move_by_offset() findet ihr unter https://www.selenium.dev/documentation/webdriver/actions_api/mouse/#offset-from-element. Alternativ kann die Maus auch von der linken oberen Ecke des aktuell angezeigten Bereichs um eine bestimmte Pixelanzahl bewegt werden (siehe dazu die Selenium-Dokumentationsseiten).
Das Vorgehen mit .move_by_offset() ist jedoch ziemlich ungenau, weil sich die Größe des Browserfensters und entsprechend der Seiteninhalte von Gerät zu Gerät unterscheiden kann. Diese Methode sollte deswegen als eine Art “last resort” behandelt werden.
9.3.2. Scrollvorgang simulieren und Seiteninhalte laden#
Nachdem das Popup-Fenster geschlossen ist, muss zum Seitenende gescrollt werden, wo sich der “Show more” Button befindet. Wir sollten zunächst überprüfen, ob der Button bereits beim Aufruf der Seite geladen wird. Dazu können wir manuell zum Seitenende scrollen, mit Rechtsklick und Inspect den “Show more”-Button in den Entwicklertools anzeigen lassen, und die CSS-Klassen in die Zwischenablage kopieren, also den gesamten String “l1ovpqvx…dir-ltr”.
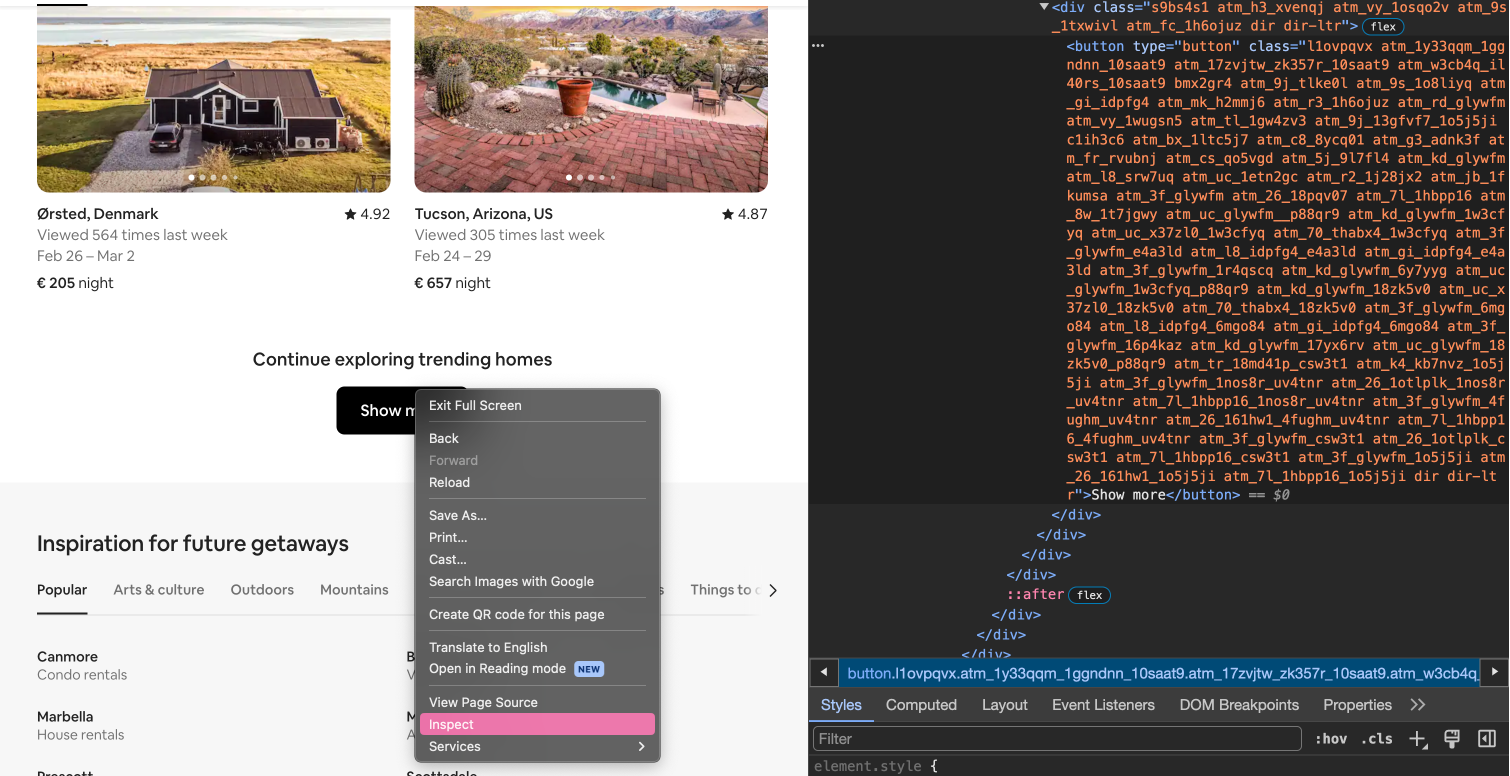
Fig. 9.11 Button-Element in den Entwicklertools.#
Anschließend laden wir die Seite neu, schließen das Popup-Fenster, und suchen in den Entwicklertools wird mit STRG-F nach dem String. Die Suche sollte keine Ergebnisse liefern. Wenn wir jedoch zum Seitenende scrollen und erneut nach dem String suchen, wird das Element nun gefunden und die Suche liefert ein Ergebnis. Das bedeutet: Die Seiteninhalte werden auf der airbnb.com-Startseite erst dann geladen, wenn sie sich im aktuellen Anzeigebereich befinden. Diesen Umstand können wir auch überprüfen, indem wir mit Selenium mit .find_element() nach dem Button mit suchen: Die Suche produziert die Fehlermeldung “NoSuchElementException”. Um die restlichen Unterkünfte auf der Startseite sowie den “Show more” Button zu laden, müssen wir also zunächt bis zum Seitenende scrollen.
In Selenium gibt es verschiedene Möglichkeiten, einen Scrollvorgang zu simulieren. Wenn bereits alle Elemente geladen wurden und nur ein Element in den aktuellen Anzeigebereich gescrollt werden soll, kann die Methode .scroll_to_element() verwendet werden (siehe Selenium-Dokumentationsseite). Wie wir gesehen haben, wird der “Show more” Button zusammen mit den restlichen Inhalten allerdings erst durch das Scrollen mithilfe von Javascript in das HTML-Gerüst der Webseite eingefügt. Das gesuchte button-Element wird also beim Aufruf der Seite noch nicht gefunden und die Methode .find_element() produziert entsprechend eine Fehlermeldung “NoSuchElementException”. Wir könnten uns aber diesen Umstand zunutze machen und beispielsweise so lange scrollen, bis das gesuchte Element gefunden wird. Bevor wir diese Strategie umsetzen können, müssen wir allerdings noch ein Thema kennenlernen, das wir erst nächste Woche besprechen.
Etwas allgemeiner und einstiegsfreundlicher ist der folgende Ansatz, bei dem so lange um eine bestimmte Pixelanzahl nach unten gescrollt wird, bis der bereits durchscrollte Bereich zusammen mit dem aktuell angezeigten Bereich größer oder gleich der Gesamthöhe der Webseite in Pixeln ist.
# Variablen für das Scrollen festlegen
# scroll_pause_time = 2 # Pausieren zwischen den Scroll-Vorgängen
# scroll_step = 300 # Schrittgröße für jeden Scroll-Vorgang (in Pixeln)
# Erste Seite bis zum Ende scrollen
# while True:
# # Um eine feste Pixelanzahl scrollen
# driver.execute_script(f"window.scrollBy(0, {scroll_step});")
# time.sleep(scroll_pause_time)
# # Scroll-Höhe nach dem Scrollen aktualisieren
# scroll_height = driver.execute_script("return document.body.scrollHeight;")
# # Abbruchkriterium: überprüfen, ob das Ende der Seite erreicht ist
# window_inner_height = driver.execute_script("return window.innerHeight;")
# if driver.execute_script("return window.scrollY;") + window_inner_height >= scroll_height:
# break
Zum Verständnis des Codes ist an dieser Stelle ein bisschen JavaScript-Kenntnis (bzw. Recherche in den JavaScript-Dokumentationsseiten) erforderlich:
.scrollBy()ist eine JavaScript-Methode, die laut Dokumentationsseite das im Browserfenster geöffnete HTML-Dokument um die angegebene Pixelanzahl scrollt. Das erste Argument gibt dabei die Pixel an, um die in horizontaler Richtung gescrollt werden soll. Das zweite Argument gibt die Pixel für das vertikale Scrollen an..scrollYist eine Eigenschaft des JavaScript-Objekts window. Das window-Objekt stellt das Browserfenster dar. .scrollY gibt laut Dokumentationsseite die Anzahl an Pixeln an, um die das HTML-Dokument bereits in vertikaler Richtung durchscrollt wurde, also die aktuelle Scroll-Position in vertikaler Richtung. In einem Kartesischen Koordinatensystem wäre die vertikale Richtung durch die Y-Achse repräsentiert (daher der Name scrollY)..scrollHeightist eine Eigenschaft des JavaScript-Objekts document.body, das laut Dokumentationsseite die Höhe eines HTML-Elements in Pixeln angibt, und zwar sowohl für den sichtbaren als auch für den unsichtbaren Bereich, also die Gesamthöhe der scrollbaren Inhalte. Mit “unsichtbarer Bereich” ist der Bereich gemeint, der aufgrund des Scrollens außerhalb des aktuell sichtbaren Bereichs liegt. Mit document.body wird das HTML-Element angegeben, dessen Höhe bestimmt werden soll: In diesem Fall wählen wir das body-Element, weil es den gesamten darstellbaren Webseiteninhalt umfasst..innerHeightist eine Eigenschaft des JavaScript-Objekts window. Es gibt laut Dokumentationsseite die innere Höhe des Browserfensters in Pixeln an, also den Bereich, in dem tatsächlich die Webseite angezeigt wird, ohne die URL-Zeile, die Tabs, usw.
return ist das JavaScript-Pendant zur return-Anweisung in Python, die in Funktionsaufrufen verwendet wird, um einen Wert zurückzugeben. Wie genau diese Werte extrahiert werden, müssen wir nicht unbedingt wissen, um den Code zu verwenden. Aber wenn sich jemand nähergehend damit beschäftigen möchte, empfehle ich diese Seite.
Note
Aber Achtung: .innerHeight ist die Höhe inklusive der Scrollleiste, die Höhe ohne die Scrolleiste wird mit .clientHeight angegeben. Für unser Beispiel ist auch der Wert für .innerHeight geeignet, aber je nach Anwendungsfall kann es ratsam sein, beim Scrollen etwas präziser vorzugehen und die Eigenschaft .clientHeight zu verwenden. Mehr dazu hier.
Den Zusammenhang zwischen den verschiedenen Objekteigenschaften und ihre Bedeutung für Abbruchbedingung der while-Schleife lässt sich vielleicht ungefähr so veranschaulichen:
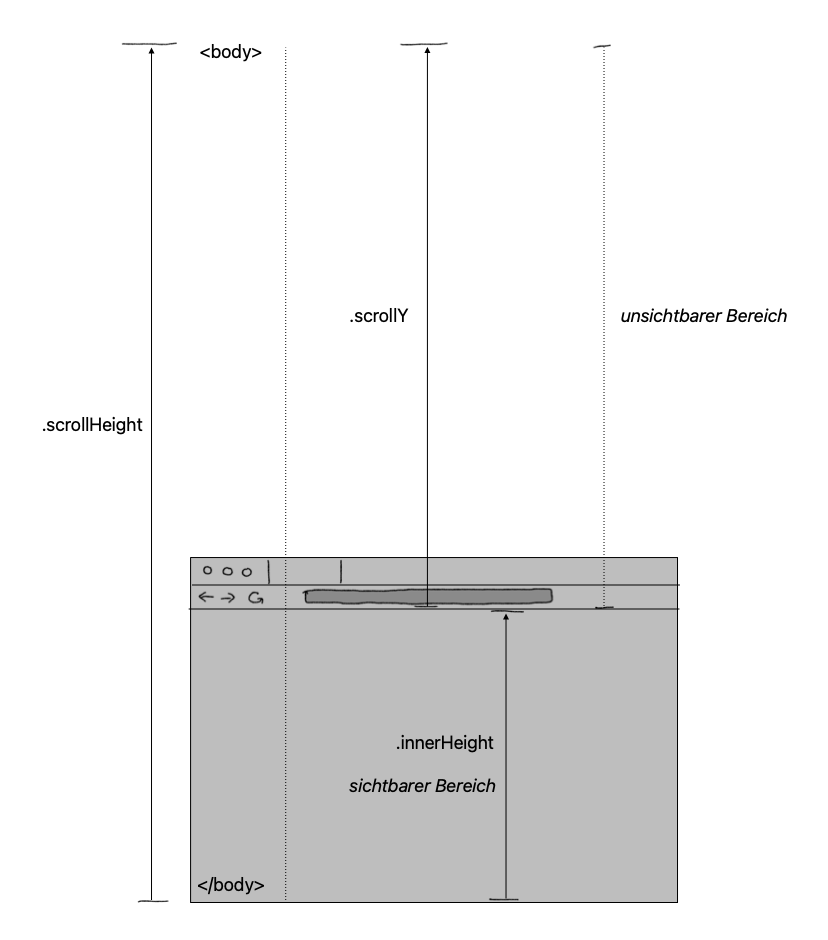
Fig. 9.12 Veranschaulichung der JavaScript-Objekteigenschaften zur Formulierung der Abbruchbedingung.#
Wenn das Seitenende erreicht ist und die while-Schleife terminiert, kann der Mausklick auf den “Show more”-Button simuliert werden. Anschließend sollte wieder ein paar Sekunden gewartet werden, damit die neuen Inhalte laden können.
# Button "Show More" klicken
# more_button = driver.find_element(By.XPATH, "//button[contains(text(), 'Show more')]")
# driver.execute_script("arguments[0].click();", more_button)
# time.sleep(5)
Anschließend muss wieder bis zum Seitenende gescrollt werden, damit alle Unterkünfte laden. “Laden” bedeutet hier zur Erinnerung, dass die neuen Inhalte in das HTML-Gerüst eingefügt werden und dadurch addressierbar werden. Der manuelle Scrollvorgang hat gezeigt, dass die Inhalte dynamisch geladen werden, sobald sie durch Scrollen in den sichtbaren Bereich gelangen. Aber anders als bei einem “echten” Infinite Scrolling endet die Seite nach einigen Scrollvorgängen. Wir könnten also beim Scrollen genauso vorgehen, wie beim Scrollen zum “Show more”-Button. Allerdings war dieser Scrollvorgang recht langsam, weil in jedem Schleifendurchlauf nur um 300 Pixel gescrollt wurde. Wir könnten also, um den Vorgang etwas zu beschleunigen, zum Beispiel die Pixelanzahl vergrößern. Hierbei sollte allerdings Folgendes bedacht werden: Je nachdem, wie groß das Browserfenster auf unterschiedlichen Geräten ist, haben auch die Kacheln mit den Unterkünften eine unterschiedliche Größe und es gibt unterschiedlich viele Kacheln in einer Zeile. Es werden also je nach Größe des Browserfensters verschieden viele Kacheln geladen, wenn um 300, 500 oder 800 Pixel gescrollt wird. Wenn zu schnell gescrollt wird, dann können Inhalte nicht rechtzeitig geladen werden, und wenn das passiert, werden sie folglich von unserem Webscraper nicht gefunden.
Zum Scrollen verwenden wir deswegen diesmal einen etwas zeiteffizienteren alternativen Ansatz, bei dem in jedem Schleifendurchlauf nicht um eine feste Pixelanzahl gescrollt wird, sondern um die innere Höhe des Browserfensters.
# Variablen für das Scrollen festlegen
# scroll_pause_time = 2 # Zwei Sekunde pausieren
# window_inner_height = driver.execute_script("return window.innerHeight;")
# i = 1
# Nächste Seite bis zum Ende scrollen:
# while True:
# # Um die innere Höhe eines Browserffensters scrollen
# driver.execute_script(f"window.scrollTo(0, {window_inner_height}*{i});")
# # Kurze Zeit warten, damit die Seite nach jedem Scroll-Vorgang laden kann
# time.sleep(scroll_pause_time)
# # Scroll-Höhe nach dem Scrollen aktualisieren, da sich die Scroll-Höhe nach dem Scrollen der Seite ändern kann
# scroll_height = driver.execute_script("return document.body.scrollHeight;")
# # Aktuelle Scroll-Position abrufen
# scroll_position = driver.execute_script("return window.scrollY;")
# # Schleife beenden, wenn die Höhe, zu der wir scrollen müssen, größer ist als die gesamte Scroll-Höhe
# if scroll_position + window_inner_height >= scroll_height:
# break
# i += 1
Wenn die Schleife terminiert, ist der gesamte Seiteninhalt durchscrollt und gerendert. Anschließend können wieder die Ortsangaben extrahiert werden: find_elements() findet jetzt nicht nur die ersten 20 Suchergebnisse, sondern alle Ergebnisse. Hierzu können wir wieder entweder das class-Attribut verwenden und die CSS-Klassen abkürzen, oder wir formulieren einen XPATH-Ausdruck zur Suche nach einem anderen Attribut, beispielsweise das Attribut data-testid:
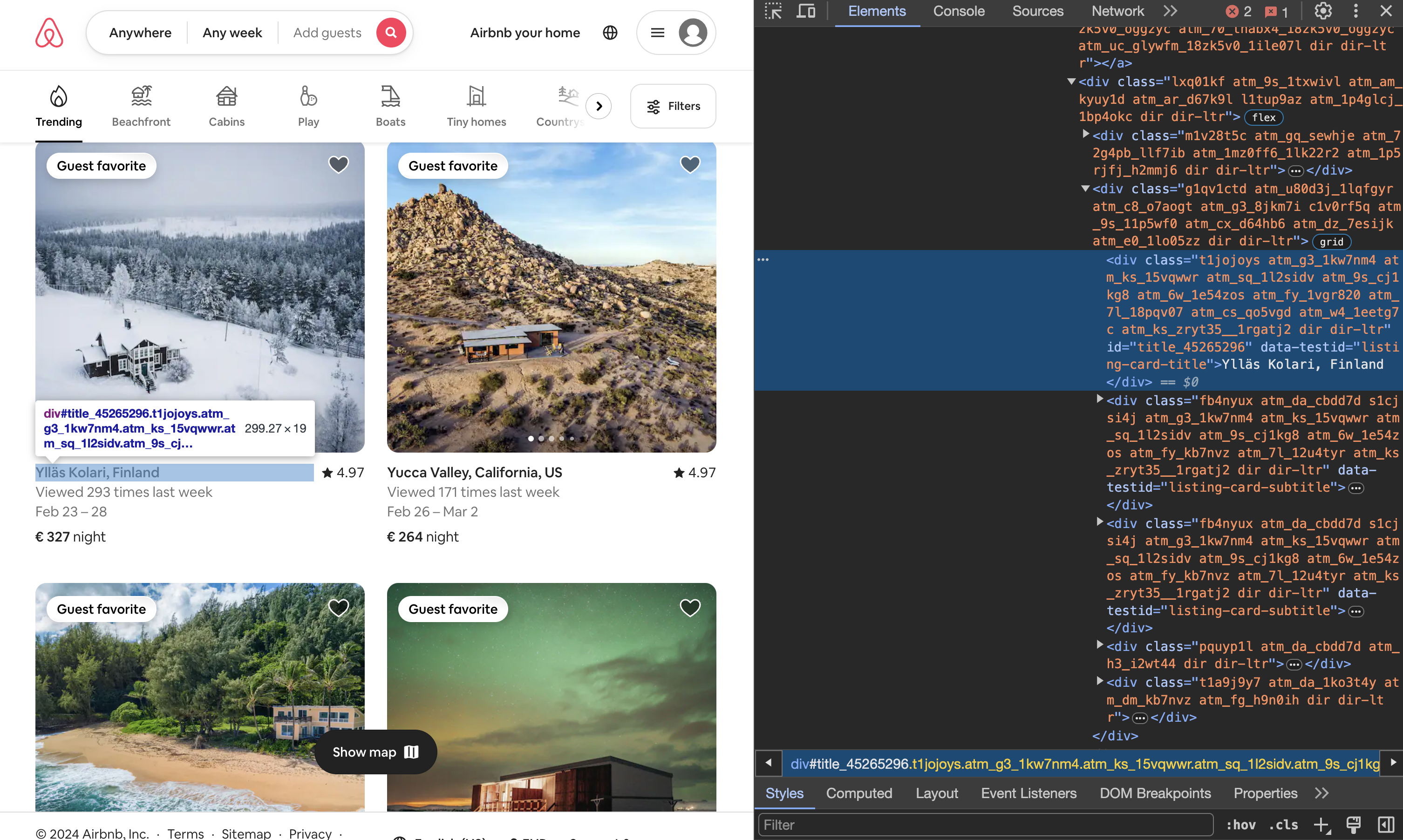
Fig. 9.13 Unterkunft in den Entwicklertools untersuchen.#
# # Daten extrahieren
# unterkuenfte = driver.find_elements(By.XPATH, "//div[@data-testid='listing-card-title']") # Alternativ By.CLASS_NAME, "t1jojoys"
# unterkuenfte_orte = [unterkunft.text for unterkunft in unterkuenfte]
# unterkuenfte_orte
Zuletzt schließen wir das aktuelle Browserfenster und die Session, also die Sitzung, welche durch den Aufruf des Chrome Webdrivers gestartet wird:
# driver.quit()
Zum Abschluss möchte ich noch auf diesen vierten Ansatz zum Scrollen mithilfe von Selenium von David Shivaji verweisen. Überlegt selbst: Welche Vor-/Nachteile hat dieser Ansatz? Welche Parameter werden dabei verwendet?
9.3.3. Suche benutzen und Tastatureingabe simulieren#
Bisher haben wir die Ortsangaben zu Unterkünften extrahiert, die zufällig auf der Startseite angezeigt wurden. Meistens interessieren wir uns aber für ganz bestimmte Daten, zum Beispiel nur Unterkünfte in Berlin zu einem bestimmten Zeitpunkt. Als nächstes sehen wir uns also an, wie mithilfe von Selenium die Suchmaske auf airbnb.com verwendet werden kann und wie eine Tastatureingabe getätigt werden kann.
Zunächst starten wir wieder den Webdriver und senden eine Anfrage für die Seite https://www.airbnb.com/ und schließen das Popup-Fenster. Beachtet allerdings, dass wir ein zusätzliches Modul importieren, das wir später zur Simulation der Tastatureingabe benötigen.
# from selenium import webdriver
# from selenium.webdriver.common.by import By
# from selenium.webdriver.common.keys import Keys
# import time
# driver = webdriver.Chrome()
# driver.get("https://www.airbnb.com/")
# time.sleep(5)
# # Popup-Fenster wegklicken
# close_button = driver.find_element(By.XPATH, "//button[@aria-label='Close']")
# driver.execute_script("arguments[0].click();", close_button)
# time.sleep(5)
Als nächstes wollen wir nach Unterkünften in Berlin suchen. Dazu führen wir die Suche wieder zuerst in unserem regulären Chrome Browser aus, um herauszufinden, mit welchen Bestandteilen des User Interfaces bei der Suche interagiert werden muss. Als erstes geben wir “Berlin” in das Suchfeld ein. Im regulären Chrome-Browser können wir, wieder mithilfe der Entwicklertools, feststellen, dass das Suchfeld über ein HTML-input-Element dargestellt wird:
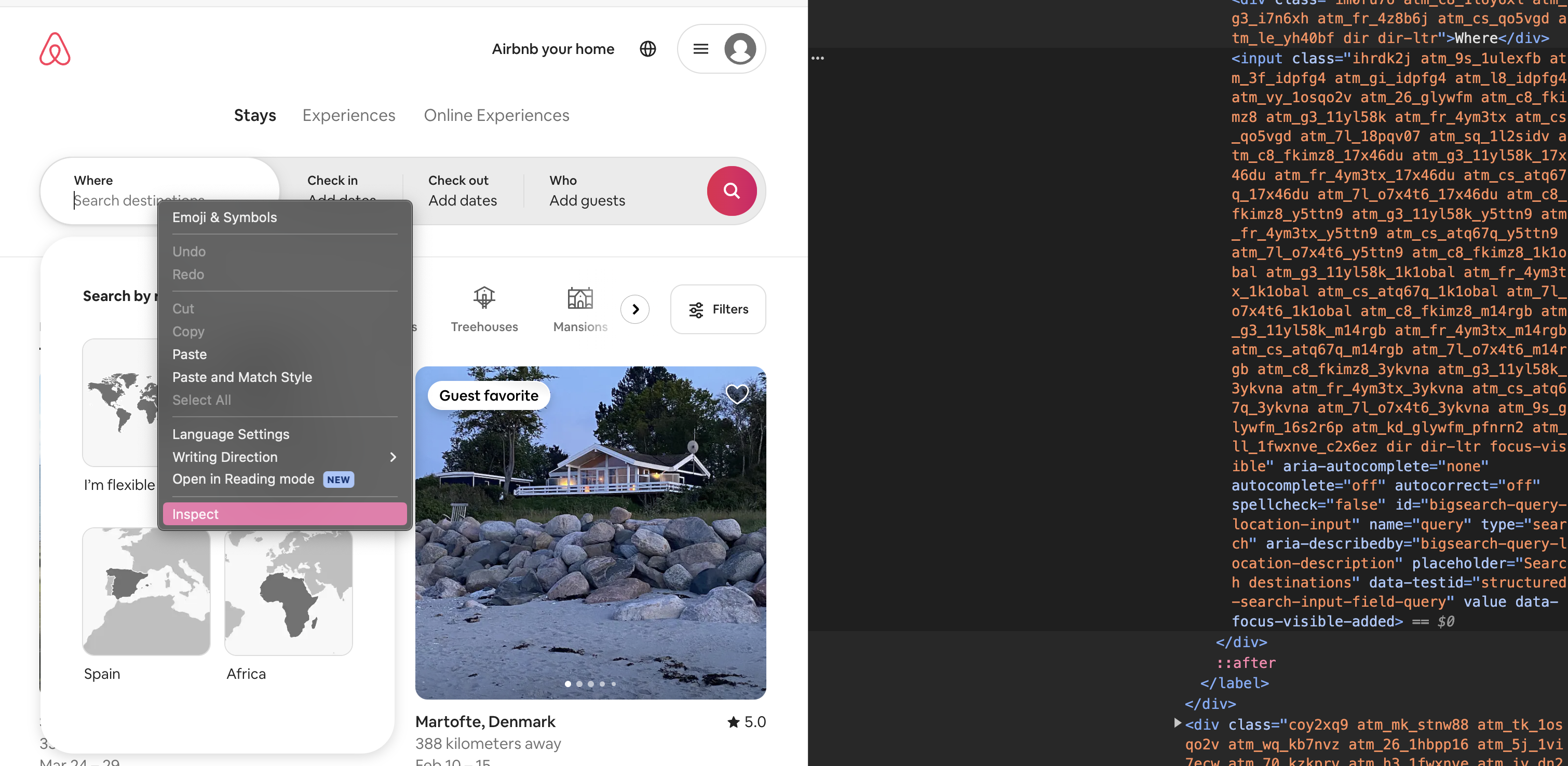
Fig. 9.14 Suchfeld in den Entwicklertools untersuchen.#
Um einen Suchbegriff eingeben zu können, muss das input-Element zunächst gefunden werden. In diesem Fall hat das gesuchte HTML-Element nicht nur ein Attribut class, sondern auch ein Attribut id mit dem Wert, “bigsearch-query-location-input”, welches erlaubt, das Element eindeutig zu identifizieren. Zur Suche können wir nun entweder .find_element(By.ID, “id_des_elements”) oder .find_element(By.XPATH, “xpath_ausdruck”) verwenden. XPath habt ihr bereits in der letzten Woche etwas kennengelernt. Wenn ihr euch unsicher seid, wie der XPath-Ausdruck formuliert sein muss, könnt ihr aber in diesem Fall die Entwicklertools zur Hilfe nehmen: Der XPath-Ausdruck, der den Pfad zu dem gesuchten Element beschreibt, kann ganz einfach mit Rechtsklick auf ein Element und die Option Copy -> Copy XPath kopiert werden:
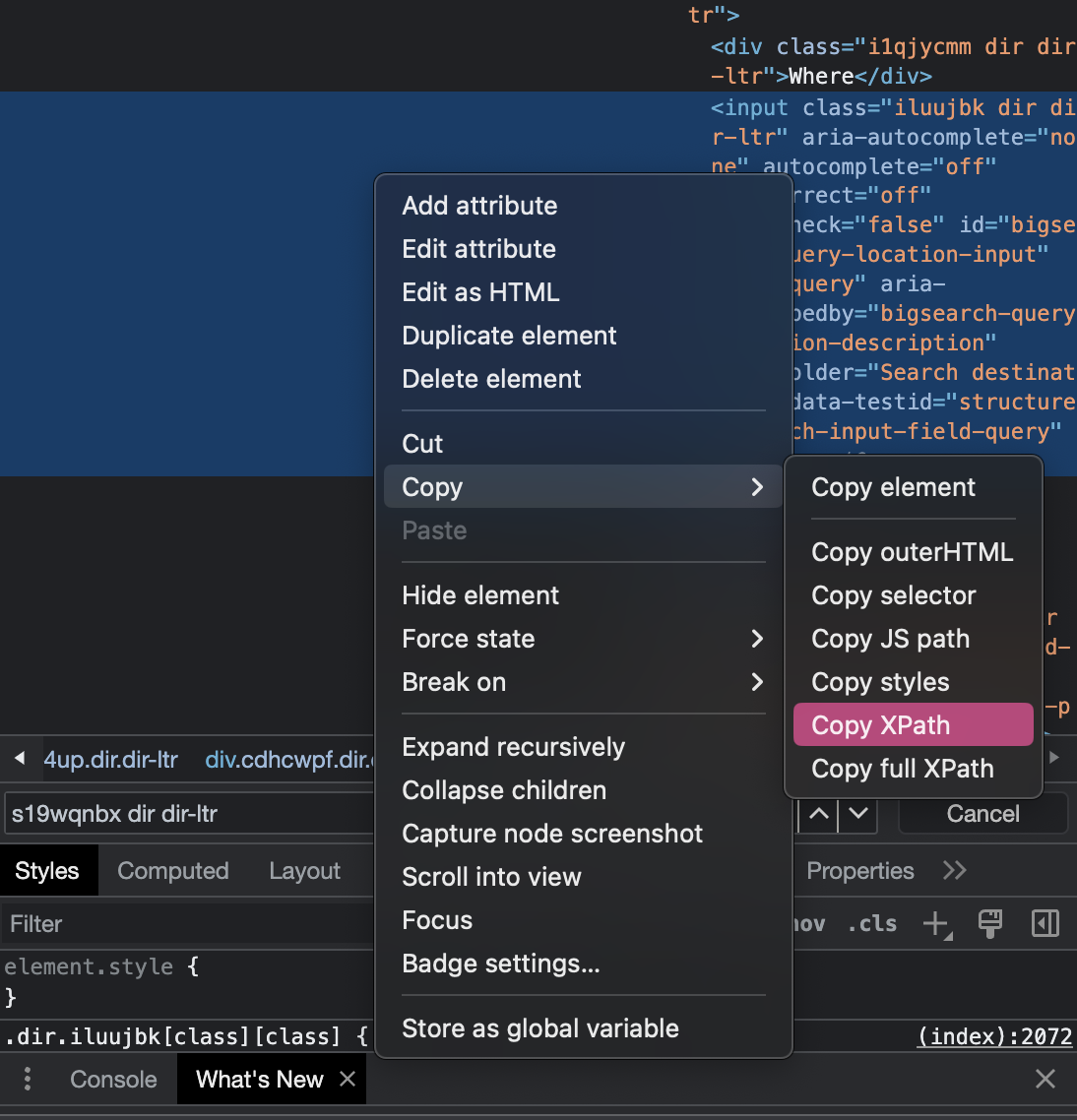
Fig. 9.15 XPath zum gesuchten Element kopieren.#
Der XPath zum gesuchten input-Element ist //*[@id=”bigsearch-query-location-input”]. Das * steht für ein beliebiges HTML-Element, aber wir können auch den Namen des HTML-Elements einsetzen, um bei vielen XPath-Ausdrücken den Überblick zu behalten:
# # Input-Element finden, in das die Suchbgegriffe eingegeben werden können
# suchfeld = driver.find_element(By.XPATH, "//input[@id='bigsearch-query-location-input']")
Beachtet, dass im Code oben die inneren Anführungszeichen angepasst wurden, um sie von den doppelten äußeren Anführungszeichen zu unterscheiden. Das ist unbedingt notwendig, weil sonst der XPath-Ausdruck nicht richtig interpretiert werden kann.
Wenn das Element gefunden wurde, kann es mithilfe der Methode .send_keys() zur Eingabe eines Suchbegriffs addressiert werden. Die Suche muss anschließend noch durch Betätigung der Enter-Taste bestätigt werden:
# # Suchbegriff eingeben
# suchfeld.send_keys("Berlin")
Die Suche muss anschließend noch durch Betätigung der Enter-Taste bestätigt werden:
# # Tasteneingabe ENTER
# suchfeld.send_keys(Keys.ENTER)
Durch Bestätigung der Suche mit Enter wird automatisch ein Fenster zur Auswahl eines Reisetermins geöffnet. Hier wollen wir die Option “flexible” auswählen. Dazu müssen wir zunächst wieder das gesuchte Element identifizieren:
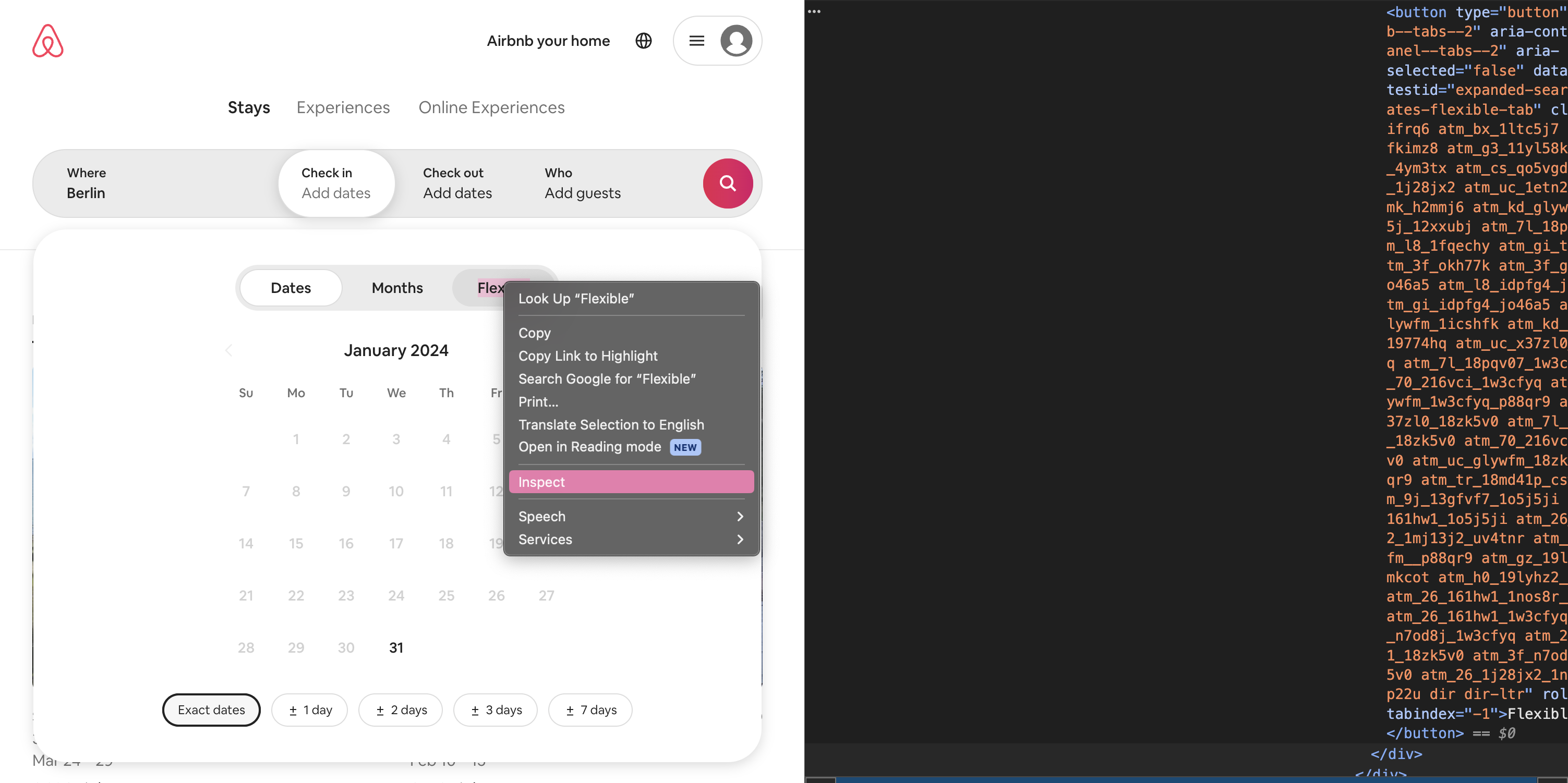
Fig. 9.16 Button “flexible” untersuchen.#
Das gesuchte HTML-Element hat wieder eine ID, über die es eindeutig identifiziert werden kann. Diesmal verwenden wir .find_element(By.ID, “id_des_elements”), damit ihr diese Verwendung der find_element-Methode auch einmal gesehen habt. Die Id könnt ihr einfach aus den Browser-Entwicklertools mit Doppelklick auf das Id-Attribut kopieren.
# # Zeit aussuchen: Flexible
# driver.find_element(By.ID, "tab--tabs--2").click()
# time.sleep(1)
Zuletzt müssen wir unsere Suche noch mit Klick auf den Suchbutton bestätigen. In diesem Fall wird über Rechtsklick auf den Suchbutton und Auswahl der Option “Inspect” allerdings wieder nicht ganz das richtige Element gefunden: Gefunden wird das span-Element mit dem Attribut class=”t1dqvypu atm_9s_1ulexfb …”; gesucht haben wir aber eigentlich den gesamten Suchbutton, also das button-Element mit dem Attribut data-testid=”structured-search-input-search-button”. Bei der Verwendung von “Inspect” ist also immer Mitdenken erforderlich, denn nicht immer wird ganz genau das Element getroffen, das gesucht wird.
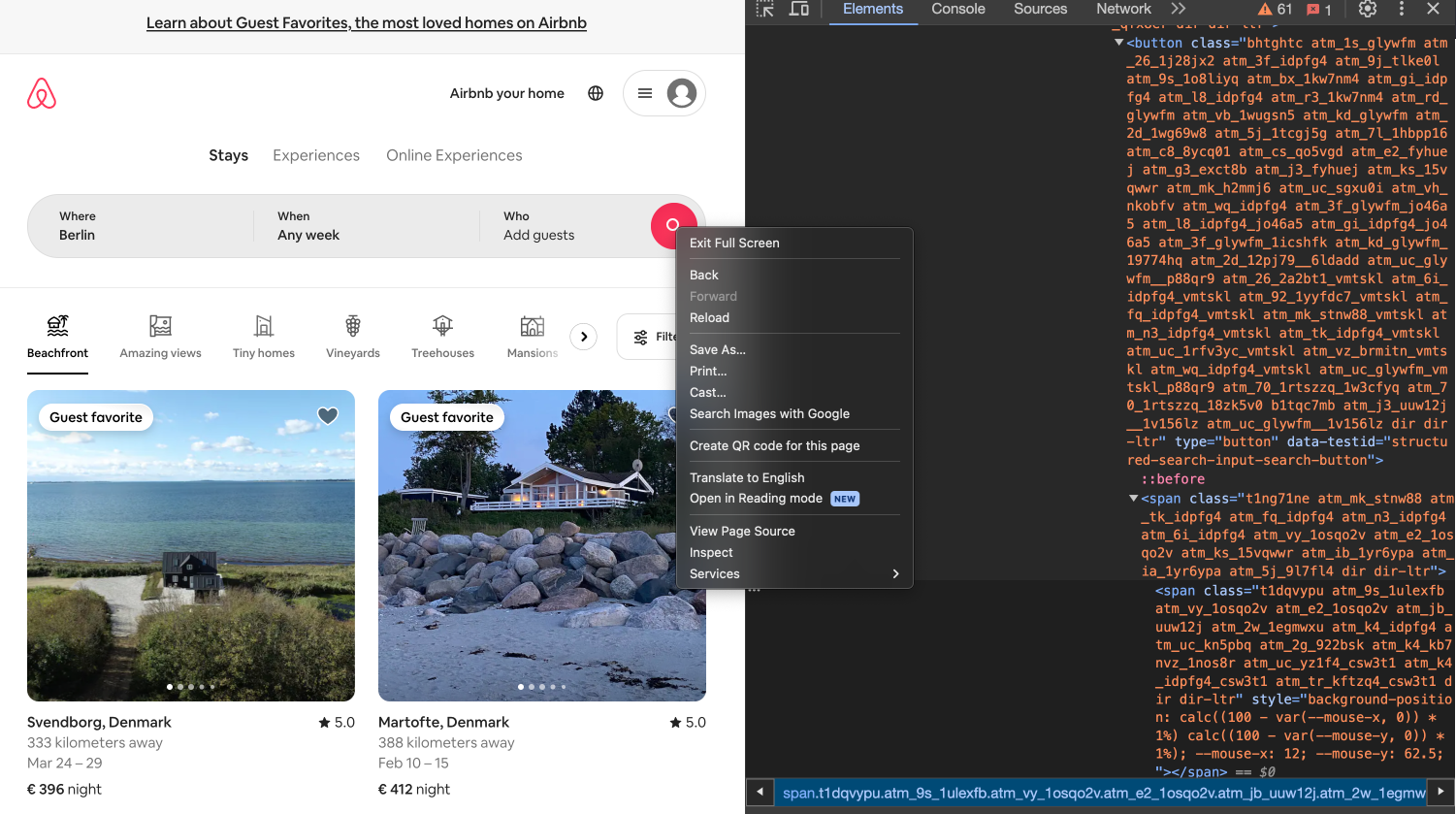
Fig. 9.17 Suchbutton untersuchen.#
Jetzt können wir den Mausklick auf den Suchbutton simulieren:
# # Auf den Suchbutton klicken: Suche bestätigen
# driver.find_element(By.XPATH, "//button[@data-testid='structured-search-input-search-button']").click()
# time.sleep(10)
Zuallerletzt führen wir wieder den Code aus der letzten Stunde aus, um alle Ortsangaben von den ersten 20 vorgeladenen Suchergebnissen zu extrahieren, und beenden die Session:
# # Orte extrahieren
# unterkuenfte = driver.find_elements(By.XPATH, "//div[@data-testid='listing-card-title']")
# unterkuenfte_berlin = [unterkunft.text for unterkunft in unterkuenfte]
# # Sitzung schließen
# driver.quit()
9.3.4. Quellen#
JavaScript-BOM-Tutorial. 2023. URL: https://www.webtechnologien.com/advanced-tutorials/javascript-bom/.
David Shivaji. How to Scroll using Selenium in Python. 2021. URL: https://davidshivaji.medium.com/how-to-scroll-using-selenium-in-python-ad1eba1e9bca.
Kuan Wei. Using Python and Selenium to Scrape Infinite Scroll Web Pages. 2020. URL: https://medium.com/analytics-vidhya/using-python-and-selenium-to-scrape-infinite-scroll-web-pages-825d12c24ec7.
MDN Contributors. Element: scrollHeight Property. 2023. URL: https://developer.mozilla.org/en-US/docs/Web/API/Element/scrollHeight.
MDN Contributors. JavaScript: return. 2023. URL: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/return?retiredLocale=de.
MDN Contributors. Window: innerHeight Property. 2023. URL: https://developer.mozilla.org/en-US/docs/Web/API/Window/innerHeight.
MDN Contributors. Window: scrollBy() Method. 2023. URL: https://developer.mozilla.org/en-US/docs/Web/API/Window/scrollBy.
MDN Contributors. Window: scrollY Property. 2023. URL: https://developer.mozilla.org/en-US/docs/Web/API/Window/scrollY.
Pylenium. Driver Commands: execute_script. 2023. URL: https://docs.pylenium.io/driver-commands/browser/execute_script.
Selenium 4 Documentation. Interacting with Web Elements. 2023. URL: https://www.selenium.dev/documentation/webdriver/elements/interactions/.
Selenium 4 Documentation. Keyboard Actions. 2023. URL: https://www.selenium.dev/documentation/webdriver/actions_api/keyboard/.
Selenium 4 Documentation. Locator Strategies: Traditional Locators. 2023. URL: https://www.selenium.dev/documentation/webdriver/elements/locators/#traditional-locators.
Selenium 4 Documentation. Mouse Actions: Offset from Element. 2023. URL: https://www.selenium.dev/documentation/webdriver/actions_api/mouse/#offset-from-element.
Selenium 4 Documentation. Working with Windows and Tabs: Execute Script. 2023. URL: https://www.selenium.dev/documentation/webdriver/interactions/windows/#execute-script.
The Modern JavaScript Tutorial. Window Sizes and Scrolling. 2024. URL: https://javascript.info/size-and-scroll-window.