10.4. Weitere Tipps und Tricks#
10.4.1. User Agent im HTTP-Header bearbeiten#
In manchen Fällen kann es notwendig sein, den Header der HTTP-Anfrage zu bearbeiten. Standardmäßig wird in einer HTTP-Anfrage über das requests-Paket als User Agent das Python requests Paket angegeben:
# Default-Header der HTTP-Anfrage
import requests
url = "https://chroniclingamerica.loc.gov/search/pages/results/?andtext=&phrasetext=book+review&format=json"
response = requests.get(url)
print(response.request.headers)
{'User-Agent': 'python-requests/2.28.2', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
Macht es einen Unterschied, ob im Header als User Agent python-requests/2.29.0 oder Mozilla/5.0 (bzw. ein anderer Brpwser) steht? Ja, denn mit dem Default-Header erkennt der Server, dass die Anfrage von einer Webscraping Bibliothek ausgeht. Manche Websitebetreiber:innen behandeln solche Anfragen anders und schränken den Zugriff für solche Anfragen ein. Allerdings darf der User Agent nicht immer geändert werden, denn manche Nutzungsbedingungen schließen so eine Art der “Vortäuschung” explizit aus.
# User Agent im Request-Header ersetzen
headers = {'User-Agent': 'Mozilla/5.0', 'Accept-Encoding': 'gzip, deflate, br', 'Accept': '*/*', 'Connection': 'keep-alive'}
response = requests.get(url, headers=headers)
Wenn eine requests Session verwendet wird, muss der Header sogar nicht im Gesamten ersetzt werden, sondern es können einzelne Werte ganz einfach ausgetauscht werden. Die offiziellen requests-Dokumentationsseiten nennen dazu das folgende Anwendungsbeispiel:
# s = requests.Session()
# s.auth = ('user', 'pass')
# s.headers.update({'x-test': 'true'})
10.4.2. Selenium Waits statt time.sleep()#
Bisher haben wir immer die Funktion sleep() aus dem Modul time verwendet, um beim Web Scrapen mithilfe von Selenium Wartezeiten einzufügen, die sicherstellen, dass der automatisierte Browser genug Zeit zum Laden der gesuchten Inhalte hat. Das Selenium webdriver-Modul bietet aber eigene Methoden, die ermöglichen, nicht nur eine feste Anzahl an Sekunden zu warten, sondern beim Warten verschiedene Strategien anzuwenden. Zum Beispiel ermöglicht die Methode driver.implicitly_wait(x), x Sekunden lang auf ein konkretes gesuchtes Element zu warten. Am Beispiel der Suche nach den Airbnb-Ortsangaben sieht die Verwendung von implicitly_wait() anstelle von time.sleep() so aus:
# from selenium import webdriver
# from selenium.webdriver.common.selenium_manager import SeleniumManager
# from selenium.webdriver.common.by import By
# import time
# driver = webdriver.Chrome()
# driver.get("https://www.airbnb.com/")
# driver.implicitly_wait(10) # implicit wait statt time.sleep()
# unterkuenfte = driver.find_elements(By.CLASS_NAME, "t1jojoys.dir.dir-ltr")
# unterkuenfte_orte = [unterkunft.text for unterkunft in unterkuenfte]
# unterkuenfte_orte
Die Verwendung von driver.implicitly_wait(x) ist effizienter als die Variante mit time.sleep(x), denn während die Ausführung des Skripts mit time.sleep(x) immer um genau x Sekunden verzögert wird, wird mit implicitly_wait(x) maximal x Sekunden gewartet. In vielen Fällen ist die Wartezeit aber kürzer, weil das gesuchte Element schon früher, vor Ablauf der x Sekunden geladen ist.
Zusätzlich gibt es in Selenium die Möglichkeit, das Verhalten des Browsers beim Laden von Inhalten im Gesamten zu steuern, und zwar mithilfe der Option pageLoadStrategy. Mehr dazu findet ihr in den Selenium-Dokumentationsseiten.
10.4.3. Suche nach verschiedenen Kindelementen mit derselben Klasse#
Manchmal ist es schwierig, ein Element eindeutig mithilfe von driver.find_elements(By.CLASS_NAME,…) zu finden. Ein Beispiel ist wieder die Airbnb-Seite: das Div-Element, das die Metadaten zu den gefunden Unterkünften enthält, hat zwei Kindelemente mit derselben Klasse: “fb4nyux s1cjsi4j dir dir-ltr”. Die Suche mithilfe der Funktion driver.find_elements(By.CLASS_NAME,”fb4nyux.s1cjsi4j.dir.dir-ltr”) würde beide Div-Elemente liefern. Aber was macht man, wenn nur eins der beiden Elemente gesucht ist, oder wenn die Elemente separat gefunden werden sollen, beispielsweise, weil sie in zwei verschiedenen Spalten eines Dataframes übertragen werden sollen?
Fig. 10.18 Beispiel: Kindelemente mit derselben Klasse#
In diesem Fall empfiehlt es sich, mithilfe von XPath nach CSS-Selektoren zu suchen. Wie das geht, ist hier beschrieben: https://www.w3docs.com/snippets/css/how-to-find-an-element-by-css-class-name-with-xpath.html. Der XPath-Ausdruck muss in diesem Fall selbst geschrieben werden: Der Ausdruck “//div[@class=’g1qv1ctd c1v0rf5q dir dir-ltr’]/div[2]” beschreibt den Pfad zum zweiten div-Element, das ein Kindelement eines div-Elements mit dem Attribut class=’g1qv1ctd c1v0rf5q dir dir-ltr’. Ihr könnt überprüfen, ob ein XPath-Ausdruck das gesuchte Element findet, indem ihr in den Entwicklertools mit Ctrl bzw. Cmd + F die Suche öffnet und den Xpath-Ausdruck einfügt:
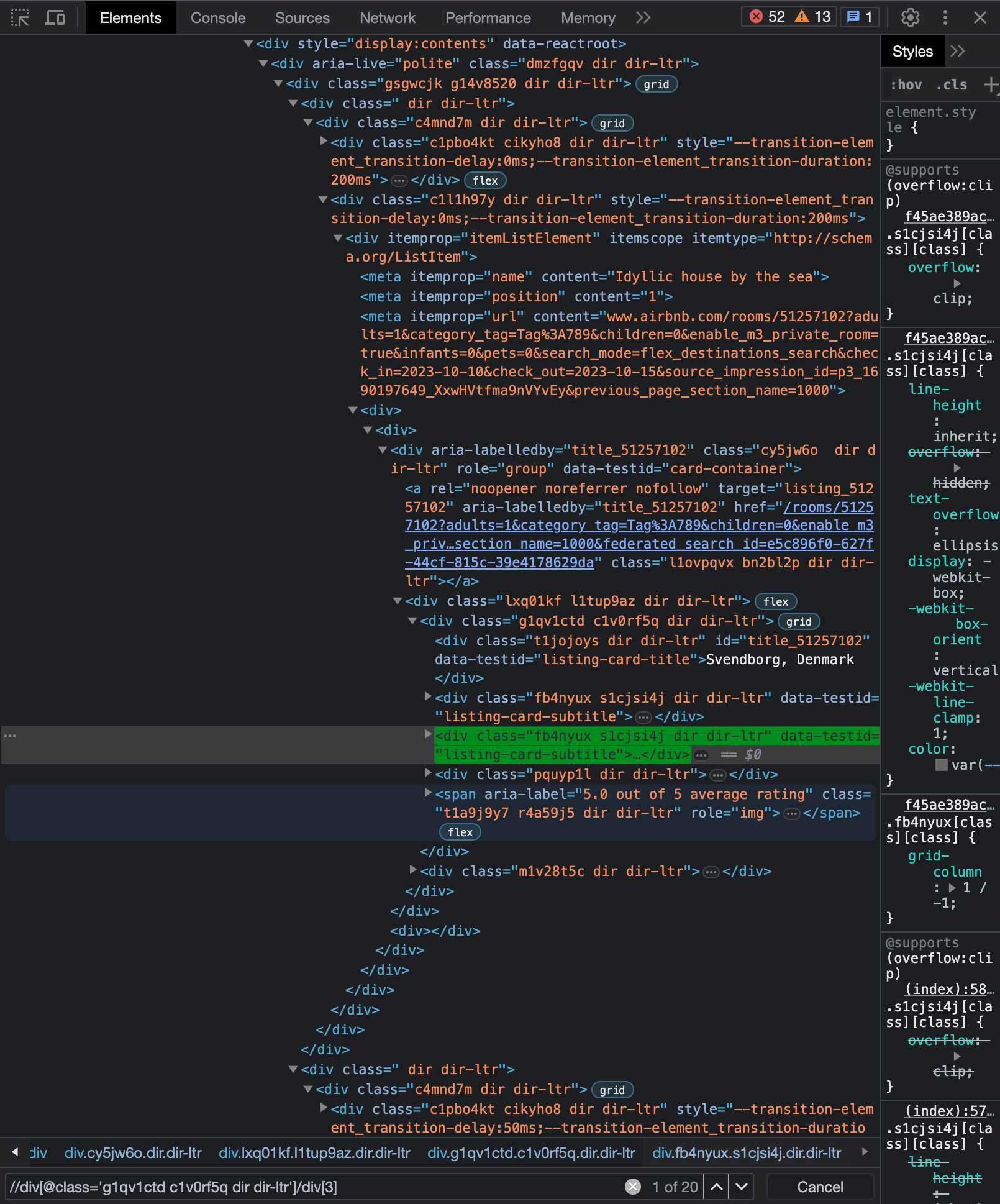
Fig. 10.19 Beispiel: Suche nach XPath-Ausdruck in den Browser-Entwicklertools#
Note
Wenn XPath zur Suche nach dem class-Attribut verwendet wird, müssen Leerzeichen nicht durch Punkte ersetzt werden.
# from selenium import webdriver
# from selenium.webdriver.common.selenium_manager import SeleniumManager
# from selenium.webdriver.common.by import By
# url = "https://www.airbnb.com/"
# driver = webdriver.Chrome()
# driver.get(url)
# driver.implicitly_wait(10)
# Suche nach zweitem und drittem Kindelement der div mit dem Attribut class='g1qv1ctd c1v0rf5q dir dir-ltr'
# driver.find_elements(By.XPATH, "//div[@class='g1qv1ctd c1v0rf5q dir dir-ltr']/div[2]")
# driver.find_elements(By.XPATH, "//div[@class='g1qv1ctd c1v0rf5q dir dir-ltr']/div[3]")
# driver.quit()
10.4.4. Dateinamen vor dem Speichern bearbeiten#
Bisher haben wir Metadaten immer genauso, wie sie sind, als Dateinamen verwendet. Das ist aber nicht immer möglich oder gewünscht. Dateinamen können mithilfe von sogenannten regulären Ausdrücken und der Funktion sub() aus dem Paket re bearbeitet werden. Reguläre Ausdrücke (engl. regular expressions) sind eine eigene Sprache zur Suche nach Mustern in Strings. Damit kann sowohl nach einfachen Wörtern, Zeichen oder Zahlen gesucht werden als auch nach komplexen Mustern. Die Funktion sub() tauscht alle Sequenzen in einem String, die einem gesuchten Muster entsprechen, gegen einen neuen String aus. Die Funktion nimmt einen regulären Ausdruck, einen String, gegen den die gefundenen Sequenzen ausgetauscht werden sollen, und einen String, in dem gesucht werden soll, als Argumente an. Ein Beispiel:
import re
title = "Arizona sun. [volume]_19550121.txt"
title = re.sub("\\. \\[volume\\]", "", title) # Zusatz [volume] entfernen
title = re.sub(" ", "_", title) # Leerzeichen durch Unterstriche ersetzen
title
'Arizona_sun_19550121.txt'
10.4.5. Fehler, Ausnahmen und Ausnahmebehandlung#
In Python gibt es verschiedene Arten von Fehlern: zum einen Syntaxfehler (syntax errors), die verhindern, dass Code überhaupt erst ausgeführt werden kann, und zum anderen Ausnahmen (exceptions), also Fehler, die dazu führen, dass die Ausführung des Codes abgebrochen und eine Fehlermeldung angezeigt wird. Bisher haben wir immer umgangssprachlich gesagt, dass eine Fehlermeldung “angezeigt” wird. Ganz korrekt würde man aber eigentlich sagen, dass eine Ausnahme “geworfen” wird. Eine Liste aller Ausnahmen, die beim Ausfürhen von Python-Code geworfen werden können, findet sich hier: https://docs.python.org/3/library/exceptions.html#bltin-exceptions.
Grundsätzlich sollte euer Code vorbeugend mit möglichen Fehlerquellen umgehen: Wenn ihr zum Beispiel Dateien über eine API bezieht, solltet ihr bei der Wahl des Dateinamens bedenken, dass Dateinamen zum Beispiel nicht unendlich lang sein dürfen, oder dass Schrägstriche in den Dateinamen beim Schreiben der Dateien fälschlich als Dateipfade interpretiert werden können. In beiden Fällen würde jeweils eine Ausnahme geworfen werden und die Ausführung des Codes würde abbrechen. Ihr solltet euren Code also immer vorausschauend schreiben. Im Beispiel mit den Dateinamen könnten vorausschauend Metadaten für die Dateinamen ausgewählt werden, welche immer dieselbe Form haben und somit immer gültig sind, oder indem die Dateinamen vor dem Schreiben der Dateien vereinheitlicht werden. Aber nicht immer kann im Voraus abgeschätzt werden, welche Art von ungültigen Werten auftreten können. Für diesen Fall gibt es in Python spezielle Anweisungen, die erlauben, bestimmte Ausnahmen gezielt abzufangen und so ein vorzeitiges Beenden des Programms zu verhindern: sogenannte try/exept-Anweisungen.
Try/except-Anweisungen haben die allgemeine Form:

Fig. 10.20 Try/Except-Anweisungen in der allgemeinen Form#
Der Code im except-Zweig wird dabei nur dann ausgeführt, wenn beim Ausführen des Codes im try-Zweig eine Ausnahme geworfen wird. Diese einfache try/except-Anweisung kann um weitere Zweige ergänzt werden. Das bereits zuvor in diesem Kurs zitierte Handbuch von Johannes Ernesti und Peter Kaiser enthält eine Überblicksdarstellung einer komplexen try/except-Anweisung mit mehreren Zweigen, inklusive Erläuterung:
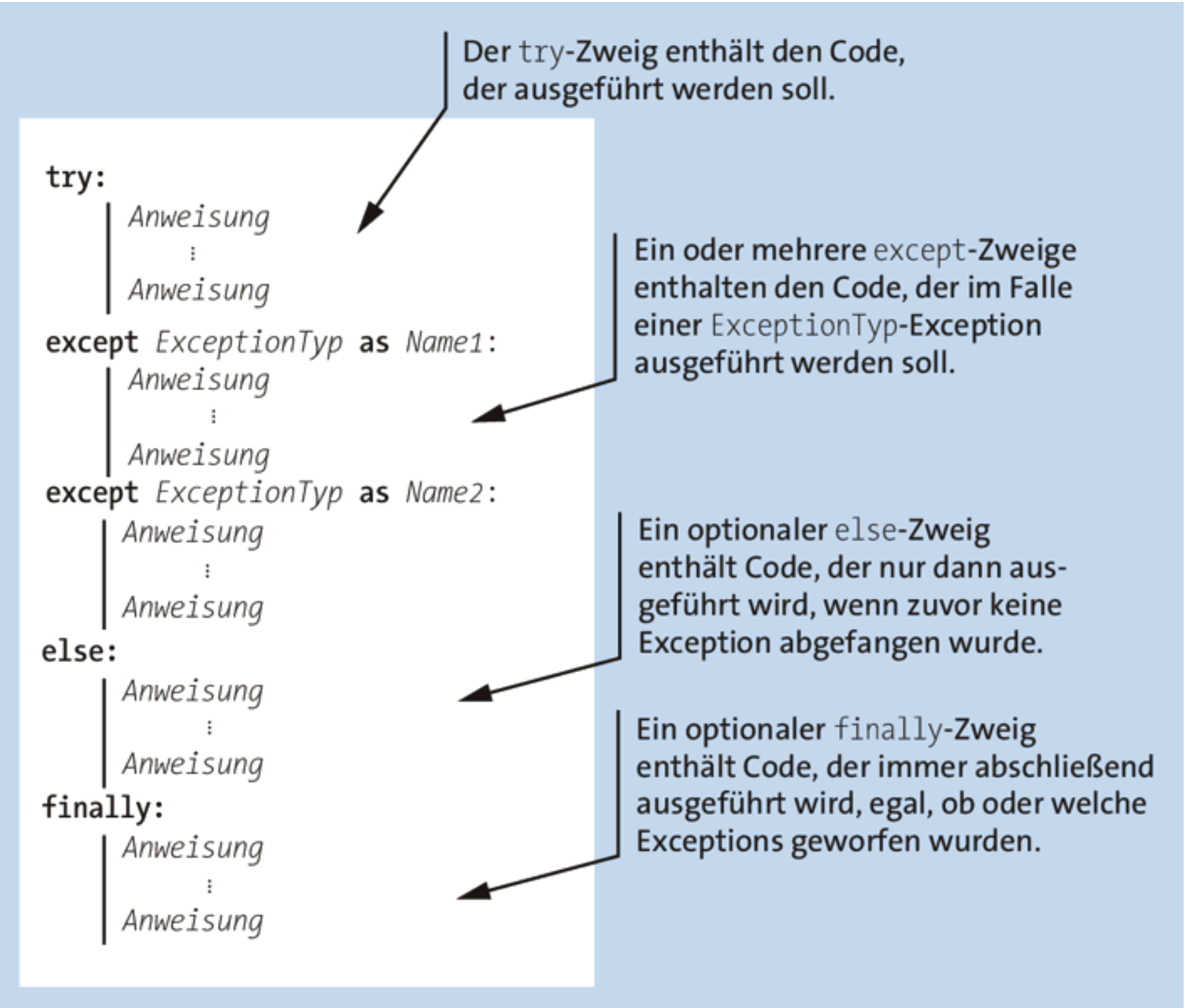
Fig. 10.21 Schaubild: try/except-Anweisung mit mehreren Zweigen. Quelle: Ernesti und Kaiser (2020).#
Beispiele und weitere Erläuterungen zum Thema Ausnahmebehandlung findet ihr im erwähnten Handbuch von Ernesti und Kaiser, in diesem Beitrag von Said van de Klundert, und natürlich in den offiziellen Python-Dokumentationsseiten.
Note
Ausnahmen sollten immer so spezifisch wie möglich abgefangen werden. Prinzipiell ist es möglich, mit except Exception alle möglichen Ausnahmen gleichzeitig abzufangen, aber das ist laut Ernesti und Kaiser (sowie den allermeisten seriösen Quellen zufolge) fast nie sinnvoll und kein guter Stil.
10.4.6. Effizienter Scrapen mit Sitemaps#
Eine Sitemap ist eine strukturierte Übersicht über alle Unterseiten einer Website. Webseitenbetreiber:innen stellen Sitemaps zur Verfügung, damit beim Crawlen der Seite durch Web Crawler verschiedener Suchmaschinen alle Unterseiten einfach gefunden werden können. Je nach gesuchten Daten können Sitemaps auch beim Web Scraping eingesetzt werden, um effizienter eine Liste von zu scrapenden Unterseiten zusammenzustellen. Sitemaps werden meist im XML-Format bereitgestellt, das heißt, dass zur Suche in solchen Sitemaps ebenfalls XPath verwendet werden kann. Sitemaps sind oft unter der Adresse www.beispielwebseite.com/sitemap.xml erreichbar, aber anders als bei der robots.txt gibt es noch einige andere typische Adressen. Eine Übersicht über solche typischen Sitemap-Adressen findet ihr hier. Manche Webseitenbetreiber:innen verlinken die Sitemap zudem in der robots.txt. Dies ist zum Beispiel bei der Website realpython.com der Fall. Die Sitemap ist hier unter https://realpython.com/robots.txt verlinkt und hat die Adresse https://realpython.com/sitemap.xml. Die Sitemap selbst sieht so aus:
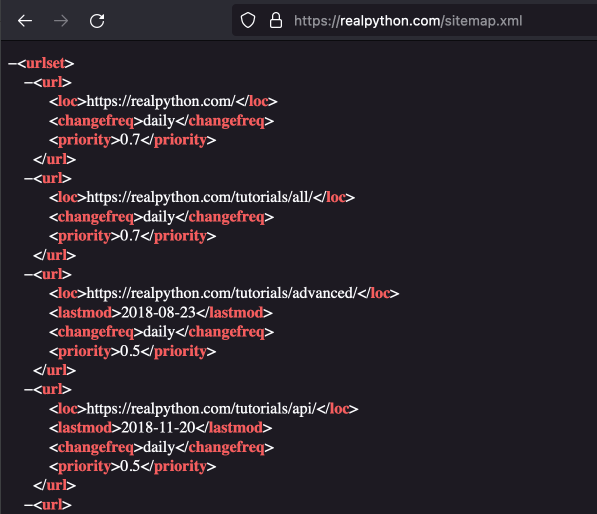
Fig. 10.22 Sitemap der Website realpython.com#
10.4.7. Sicher Scrapen#
Die Anforderungen an Sicherheit und Anonymität können sich von Web Scraping Projekt zu Web Scraping Projekt unterscheiden. Ein paar Dinge sind aber allgemein empfehlenswert: Achtet nach Möglichkeit darauf, dass in eurer Abfrage-URL https statt http steht. Falls ihr euch auf einer Webseite anmelden müsst, um Inhalte scrapen zu können, solltet ihr immer ein Profil speziell für diesen Zweck erstellen. Gebt niemals sensible Passwörter in den automatisierten Chrome Browser ein. Seid außerdem vorsichtig, wenn ihr verschiedene Tipps online lest: Bevor ihr einfach komplexen Code von stackoverflow oder einem ähnlichen Forum kopiert, recherchiert, ob es nicht vielleicht einen einfacheren Weg gibt, um euer Problem zu lösen. Denn wenn ihr gar nicht versteht, was ihr gerade macht, könnt ihr auch nicht abschätzen, welche Risiken das kopierte Vorgehen mit sich bringt, und welche Sicherheitsvorkehrungen die andere Person vielleicht vorher getroffen hat – das ist ja eigentlich selbsterklärend, aber im Eifer des Gefechts vergisst man das gerne. Es empfiehlt sich außerdem, beim Web Scrapen ganz allgemein einen Useraccount auf eurem Computer zu verwenden, der keine Administratorrechte hat. Falls doch etwas schief gehen sollte, ist dadurch der Schaden zumindest begrenzt. Je nach Web Scraping Projekt kann es empfehlenswert sein, die eigene IP Adresse mithilfe von VPN oder Proxy zu verstecken. Allerdings ist das ethisch und rechtlich eine schwierige Sache: Wir haben beispielsweise bereits besprochen, dass man sich strafbar machen kann, wenn man beim Web Scraping blockiert wird und anstatt seinen Web Scraper robots.txt-konform umzuschreiben einfach seine IP-Adresse versteckt. Hier ist also Vorsicht und Eigenrecherche geboten.
10.4.8. Don’t do this…#
Zum Schluss möchte ich euch noch eine kleine Empfehlung mit auf den Weg geben: Nicht immer ist Web Scraping wirklich die schnellste und effizienteste Lösung für euer Problem. Es macht wahrscheinlich mehr Spaß, Code zu schreiben, als direkt die Aufgabe anzugehen, aber wenn ihr unbedingt eine Deadline einhalten müsst, dann ist es natürlich auch okay, ein Web Scraping Projekt abzubrechen und eure Aufgabe einfach manuell zu lösen. Also in diesem Sinne:

Fig. 10.23 Don’t do this… Quelle: Kevin Sahin 2022#
10.4.9. Quellen#
Peter Ernesti, Johannes und Kaiser. Python 3: Ausnahmebehandlung. 2020. URL: https://openbook.rheinwerk-verlag.de/python/22_001.html.
Ognian Mikov. How to Find the Sitemap of a Website. 2021. URL: https://seocrawl.com/en/how-to-find-a-sitemap/.
Ryan Mitchell. Webscraping with Python. Collecting More Data from the Modern Web. O'Reilley, Farnham et al., 2018.
Jonathan Mondaut. Take Advantage of Sitemaps for Efficient Web Scraping: A Comprehensive Guide. 2023. URL: https://medium.com/@jonathanmondaut/take-advantage-of-sitemaps-for-efficient-web-scraping-a-comprehensive-guide-c35c6efe52d3.
Kenneth Reitz. Requests Documentation: Errors and Exceptions. 2023. URL: https://requests.readthedocs.io/en/latest/user/quickstart/?highlight=cookie#errors-and-exceptions.
Kevin Sahin. Web Scraping Using Selenium and Python. 2022. URL: https://www.scrapingbee.com/blog/selenium-python/.
Python 3.11.3 Documentation. Built-in Exceptions. URL: https://docs.python.org/3/library/exceptions.html#bltin-exceptions.
Python 3.11.3 Documentation. Compound Statements: The Try Statement. URL: https://docs.python.org/3/reference/compound_stmts.html#the-try-statement.
Python 3.11.3 Documentation. Errors and Exceptions. URL: https://docs.python.org/3/tutorial/errors.html.
Said van de Klundert. Python Exceptions: An Introduction. URL: https://realpython.com/python-exceptions/.
Selenium 4 Documentation. Browser Options: pageLoadStrategy. 2022. URL: https://www.selenium.dev/documentation/webdriver/drivers/options/#pageloadstrategy.
Selenium 4.10 Documentation. Waits. 2023. URL: https://www.selenium.dev/documentation/webdriver/waits/.
W3Docs. How to Find an Element by CSS Class Name with XPath. 2023. URL: https://www.w3docs.com/snippets/css/how-to-find-an-element-by-css-class-name-with-xpath.html.