8.3. Beispiel 2: Library of Congress API#
Die Library of Congress (LOC) bietet eine Reihe sehr gut dokumentierter APIs zur Abfrage von Metadaten, Dateien und Volltexten aus dem Bestand der Bibliothek. Eine davon ist die API der Sammlung US-amerikanischer historischer Zeitungen Chronicling America. Diese API werden wir in dieser Stunde kennenlernen.
Übersicht über die LOC APIs: https://guides.loc.gov/digital-scholarship/accessing-digital-materials#s-lib-ctab-26648178-2
Dokumentation zur Chronicling America API: https://chroniclingamerica.loc.gov/about/api/
Zunächst machen wir uns mit der Chronicling America API vertraut. Welche Daten können darüber abgefragt werden?
Für unser Beispiel werden wir die Volltexte zu allen Ergebnissen einer Suche nach Schlüsselwörtern in den Volltexten der Zeitungen abfragen und herunterladen (Abschnitt “Searching the directory and newspaper pages using OpenSearch”). Die Volltexte sind mithilfe von OCR-Verfahren erstellt, also mithilfe von automatischer Bilderkennung. Unsere Suchabfrage liefert also nur diejenigen Zeitungen, in denen die Suchwörter korrekt erkannt wurden.
8.3.1. Vorbereitung#
# wir müssen zunächst die Anaconda Einstellungen ändern, damit wir das Paket ratelimit installieren könenn:
# https://stackoverflow.com/questions/48493505/packagesnotfounderror-the-following-packages-are-not-available-from-current-cha
# import sys
# !conda config --append channels conda-forge
# Paket ratelimit installieren
# import sys
# !conda install --yes --prefix {sys.prefix} ratelimit
# Pakete importieren
import requests
import os
import math
import time
# from ratelimit import limits, RateLimitException, sleep_and_retry
8.3.2. Exploration der Chronicling America API#
Wie in der letzten Stunde müssen wir zur Abfrage von Daten wieder eine URI nach den Vorgaben der API Dokumentation zusammensetzen.
Suchabfragen können mit einem ? an die URL https://chroniclingamerica.loc.gov/search/pages/results/ angefügt werden.
Es gibt laut Dokumentationsseite drei verschiedene Abfrageparameter:
andtext: the search query
format: ‘html’ (default), or ‘json’, or ‘atom’ (optional)
page: for paging results (optional)
Diese Parameter werden wir uns der Reihe nach ansehen.
Parameter andtext
# Der andtext Parameter: Volltexte nach Schlagwörtern oder Phrasen durchsuchen
# Suche nach Schlagwörtern book AND review
url_1 = "https://chroniclingamerica.loc.gov/search/pages/results/?andtext=book+review"
url_2 = "https://chroniclingamerica.loc.gov/search/pages/results/?andtext=book%20review"
Eine aufmerksame Betrachtung der Ergebnisse der Suche nach einem Suchbegriff über die Suchmaske der Website https://chroniclingamerica.loc.gov zeigt, dass die Suche über die Suchmaske genau dieselben Ergebnisse liefert wie die API-Abfrage. Das ist nicht erstaunlich, denn die URL, die beim Verwenden der Suchmaske generiert wird, ist ganz ähnlich aufgebaut wie die URL, die wir für die API-Abfrage erstellen, mit dem einzigen Unterschied, dass die Suchparameter etwas anders aussehen:
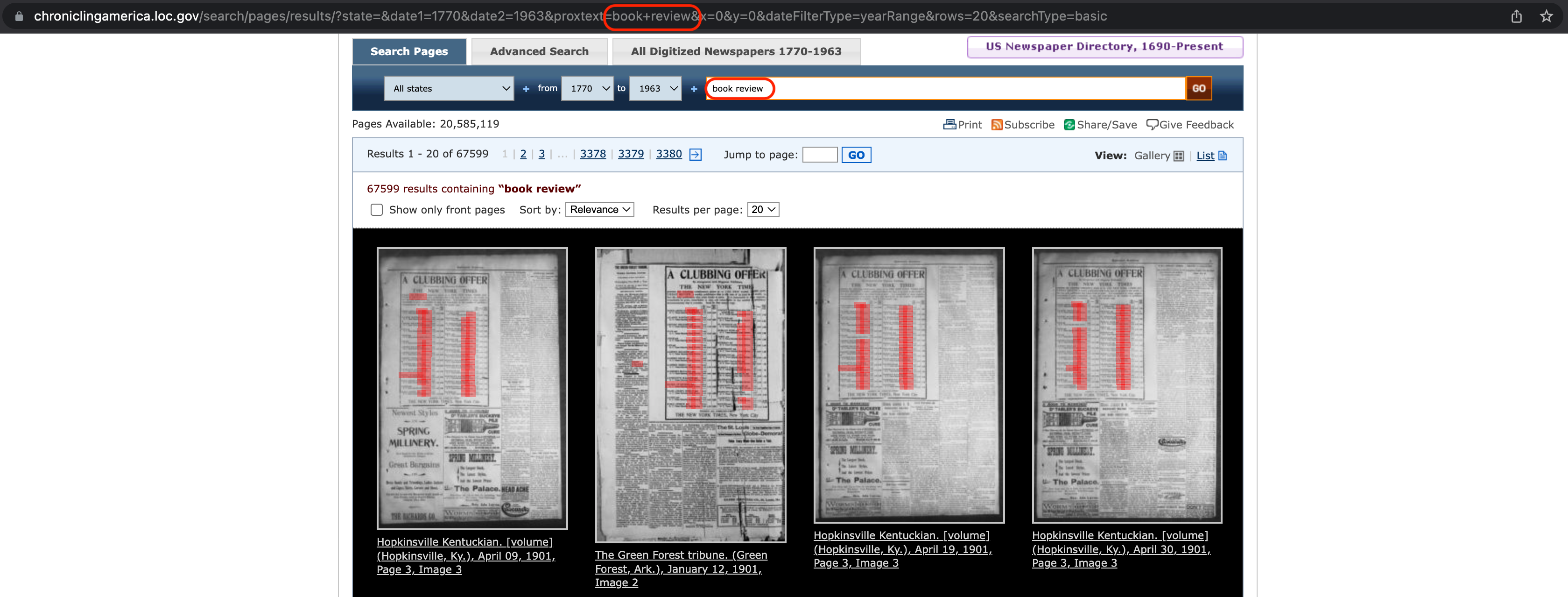
Fig. 8.3 Einfache Suche über die Suchmaske der Seite Chronicling America.#
Wir können diese URL nutzen, um den andtext-Parameter besser zu verstehen. Wenn wir in der einfachen Suche nach dem Suchbegriff “book review” suchen, dann steht in der URL “book+review”. Wenn wir stattdessen die Erweiterte Suche (Tab Advanced Search) verwenden und nach einer Phrase suchen, dann steht in der URL der Zusatz “&phrasetext=book+review”:
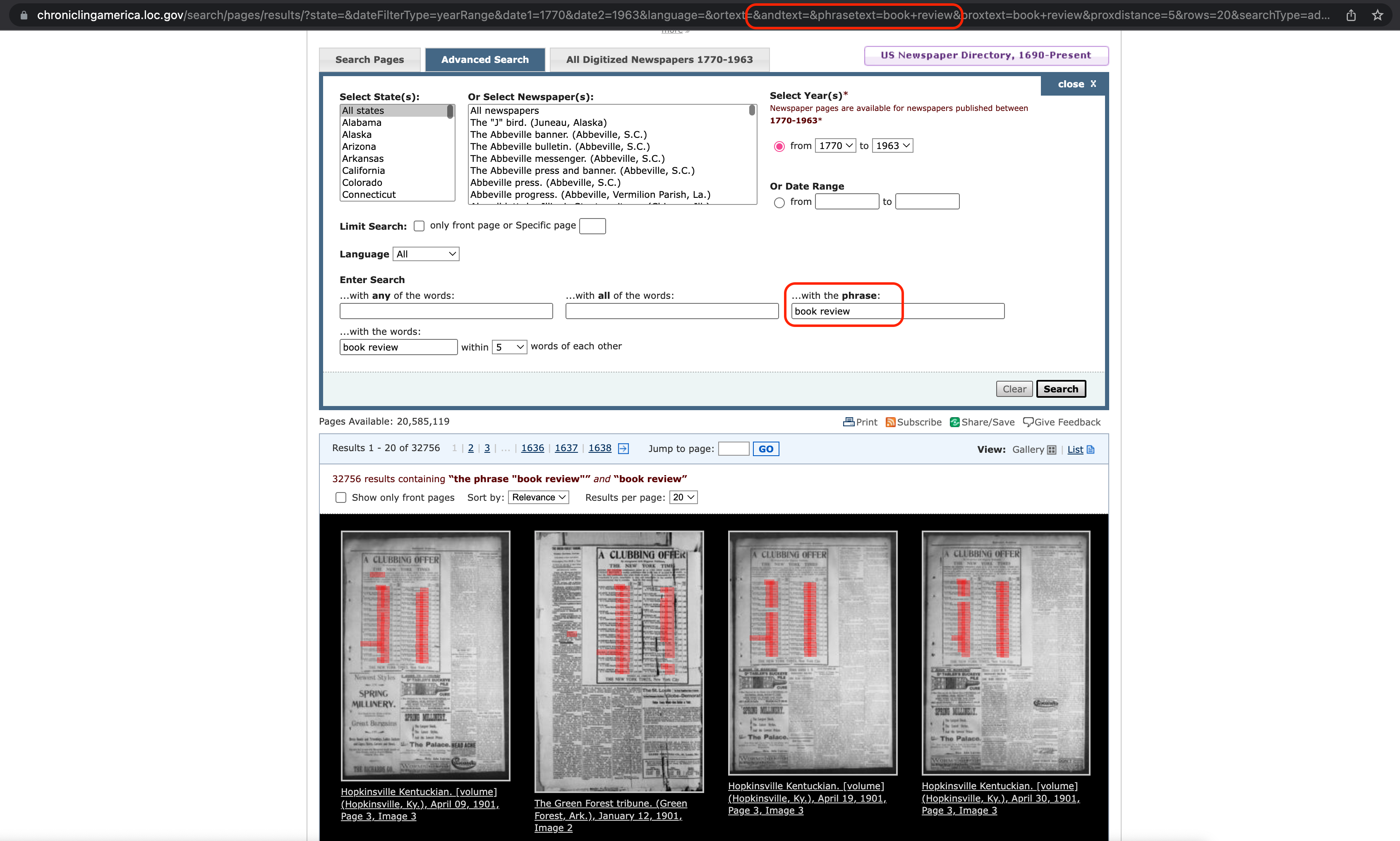
Fig. 8.4 Erweiterte Suche über die Suchmaske der Seite Chronicling America.#
Tatsächlich akzeptiert auch die Chronicling America API eine Abfrage-URI mit dem Zusatz &phrasetext:
# Suche nach Phrase "book review"
url_3 = "https://chroniclingamerica.loc.gov/search/pages/results/?andtext=&phrasetext=book+review"
# woher weiß ich das: manuelle Suche über "advanced search" und URL untersuchen
# https://chroniclingamerica.loc.gov/search/pages/results/?dateFilterType=yearRange&date1=1770&date2=1963&language=&ortext=&andtext=&phrasetext=book+review&proxtext=&proxdistance=5&rows=20&searchType=advanced
search_results = requests.get(url_3)
# search_results
Parameter format
# Der format-Parameter: Ergebnisse im JSON-Format abfragen
# https://chroniclingamerica.loc.gov/search/pages/results/?andtext=&phrasetext=book+review&format=json
# erste Seite der Suchergebnisse: 20 Ergebnisse je Seite
url = "https://chroniclingamerica.loc.gov/search/pages/results/?andtext=&phrasetext=book+review&format=json"
search_results = requests.get(url)
# search_results
Note
JSON im Chrome Browser ansehen
Zur Ansicht der JSON-Datei im Chrome Browser können wir wieder auf die Entwicklertools zurückgreifen. Die Standardansicht ist nämlich sehr schwer lesbar, weil der JSON-String nicht formatiert ist. Um eine formatierte Ansicht zu erhalten, befolgt die folgenden Schritte: Entwicklertools öffnen -> “Sources”-Tab auswählen-> Link anklicken
Parameter page
# Der page Parameter: Nur die ausgewählte Ergebnisseite abfragen
first_page = "https://chroniclingamerica.loc.gov/search/pages/results/?andtext=&phrasetext=book+review&format=json&page=1"
first_page_results = requests.get(first_page)
# first_page_results
Per Default werden immer die ersten 20 Suchergebnisse (also die erste Seite der Suchergebnisse) ausgegeben, wenn der page-Parameter weggelassen wird:
default_page = "https://chroniclingamerica.loc.gov/search/pages/results/?andtext=&phrasetext=book+review&format=json"
default_page_results = requests.get(default_page)
first_page_results.content == default_page_results.content
True
Mit diesem Wissen könenn wir eine Testabfrage durchführen.
Für unsere Abfragen wählen wir JSON als Rückgabeformat aus, weil wir den JSON-String bequem parsen können, indem wir den String in ein Python Dictionary umwandeln:
url = "https://chroniclingamerica.loc.gov/search/pages/results/?andtext=&phrasetext=book+review&format=json"
# JSON-String in Python Dictionary umwandeln
search_results = requests.get(url).json()
print(len(search_results["items"]))
20
Das Dictionary enthält einen Schlüssel “items” mit einer Liste der Suchergebnisse als Wert. Die Suchergebnisse sind selbst als Dictionaries organisiert. Jedes Suchergebnis-Dictionary enthält einen Schlüssel “ocr_eng” mit den Volltexten:
# erstes Suchergebnis auf der ersten Seite der Suchergebnisse
search_results["items"][0]["ocr_eng"]
'i\ntii\nO >\nI\ncI 1 t\ntf M\niIt ItN i J 1\nl N 4I i d iopI nU1Uf u f1tturnulr c\n1 nuCnnJ t un f if r\nP r I\nlt J =\nIII l I\nI\ni5r1 + ti f\ni iY1 t1 1\n8 6 i T n r wi i s i r r rn\nMr i t\nt Wlft l 1 pi CLUBBING OFFER\nx\n4f By arrangement with Magazine Publishers\njllg NEW YORK TIMES\nS presents the following combination prices as to THE NEW YORK TIMES SAT\nURDAY REVIEW weekly publication that is the best of its kind in the world in\nfact the only publication that treats books as news It is remarkable in many respects j\nA Iremarkable in price remarkable in size andremarkable inthe number of publishers\npublishersi\nQRM AMERICAN REVIEW and\nF < i ffl YTimes Saturday Book Review\n1y f\nr SI ATLANTIC MONTHLY and\nj I N V Times Saturday Book Review\nJ\nCENTURY MAGAZINE andi\nv i N Y Times Saturday Book Review\nh I <\ni\nPUCK and\nN Y Times Saturday Book Review\n0 u < V\nJUDGE and 1\nN1Y Times Saturday BookReview\nLIFE and\nN Y Times Saturday Book Review\ni t HARPERS MAGAZINE and\n3 N Y Times Saturday Book Review\nrJARPERS BAZAR and\nN Y Times Saturday Book Review\ni <\nHARPERS WEEKLY and\nN Y Times Saturday Book Review\nI CRIBNERS MAGAZINE and\nj N Y Times Saturday Book Review\n> r i LIPPINCOTTS MAGAZINE and\nN Y Times Saturday Book Review\nREVIEW OF REVIEWS and\n> N Y Times Saturday Book Review\nr FRANK LESLIES WEEKLY and\nt N Y Times Saturday Book Review\nlft\nOUTING and >\nN Y Times Saturday ook Review\ni\nPUBLIC OPINION and\nN Y Times Saturday Book Review\nBubacrlp tlon\ntlonlrtce\n5001\nOOI\n400 Lo\n1ob4o0\n4o0\n900Soo\n100\n500\n100\nIioo\n100\n400\n100\ni 400\n100\nI\n400\n100\n100\n250\n100\n250\n100\n400\n100\n300\n100\n250\n100\nValuerGoo\nGoo\nGooS00\n500\nI\n600\n600\n600\n500\n500\n500\n1\n400\n50\n35o\n00\n400\n350\nDaTUFon\nFOItY\n500\n400\n400\n500\n500\n5005Oo\n5Oo\n400\n40Q\n400\n325\n250\n250\n400\n300\n2501\nYOUTHS COMPANION New Sub\nscription and\nN Y Times SaturdaBobk Review\nOUTLOOK and\nN Y Times Saturday Book Review\nST NICHOLAS and\nN Y Times Saturday Book Review\nWORLDS WORK and\nN Y Times Saturday Book Review\nCRITIC and\nN Y Times Saturday Book Review\nBOOKMAN and I\nN Y Times Saturday Book Review\nINDEPENDENT and\nN Y Times Saturday Book Review\nBOOKBUYER and\nN Y Times Saturday Book Review\nMCCLURES MAGAZINE and\nN Y Tim s Saturday Book Review\nMUNSEYS MAGAZINE and\nN Y Times Saturday Book Review\nFRANK LESLIES MAGAZINE and\nN Y Times Saturday Book Review\nDELINEATOR and\nN Y Times Saturday Book Review\nEVERYBODYS MAGAZINE and\nN Y Times Saturday Book Review\nPEARSONS MAGAZINE and\nN Y Times Saturday Book Review\nCOSMOPOLITAN and\nN Y Times Saturday Book Review\nSUCCESS and\nN Y Times Saturday Book Review\nscrip Bub\nI ton\nPrice\n175\n100\n300\n100\n300\n100\n300\n100\n200\n100\n200\n100\n200\n100\n150\n100\n100\n100\n100\n100\n100\n100\n100\n100\n100\n100\n100\n100\n100\n100\n100\n100\ni\nADDRESS ALL COMMUNICATIONS\nt 1 THE NEW YORK u TIMES New York City r\nn u n\n10\nNewest Styles\n<\n> 2 IL T\n1Y\n0\nSPRING\nI\nMILLINERY\nNow Ready for thq Trade in all the\n5 Handsomest Designs v\ni\nt\nr I G i iI t Igains I\nI\nJ\nr\nHST a\nDress hoods and Trimmings Ladies Jackets\ni\nand Gapes Skirts Corsets and Shoes\n1\nI1Do not fail to see our Bargains inai kinds of\nPry Goods and in Gents Slip ts\nv Collars Ties Etc > i r\nIM 1\nr I J\n5\nS\n4 r\nf I\ni THE RICHARDS CO\n1\nA BOON TO WANKINBl\nIJWTiiJ I\nI DRT ABlER BUCKEYE\no\nCURE\nh New Discovery for the Certain Cure of INTERNAL and\nEXTERNAL PILES WTTHCOT PAIN\nCURES WHERE ALL OTHERS HAVE FAILED\nTUBES BY MAIL 75 CENTS BOTTLES 60 CENTS\nAMES F BALLARD Solo Proprietor 310 Horth Main Street ST LOUIS MO\nFor sale bv R G Hardwick druggist Hopkinsville Ky\nSPRING MILLINERY 1\nxThe Largest Stock\nI The Latest Styles\n1\nI I And the Lowest Prices\nr mmmm m a\nThe Palace\ni ew Ideas and UptoDate in everything that\nDel twins g our line VVe Solicit Your Patronage\nRespectfully t\nMrs Ada Layue\nI\ni WORMS\ni J\nvalue\n275\n400\ni\n400\n400\n300\n300\n300\n250\n200\n200\n200\n200\n200\n200\n200\n200\nDaTUFon\nnxoiiiovs\nmm\novsYEAIt\nt\n200 i\n325\n300I\n300\n20Q\n210\n235 c 1\ntkL70\n150\n150\n1\nI\nj i\nsct y\nt\n<\n140 l\nI\nt25\nr\nJ25\nI\nt1O\nPILE\nWHITES CREAM\nVERMIFUGE\nEicStlncuutail neetidQuallt I\nI For 20 Years Has Led altWoRBRom9dUs 1 f >\nfStoxp QT 47 J 1 TIDGGI II i\nPzwumrctl h\nMarriage By Phonograph\nA new use has been found for\nthe phonograph and one likely to\npopularize the instrument to a\nwonderful degree It was used in\nstead of a clergyman at a Wedding\nat Binghamton N Y and proved\nnot only a success but a delightful\ninnovation\ninnovationThe was that of a I\nyoung man to a young woman who\nhad been suffering with diptheria\nNo clergyman in the town was will\ning to brave infection and so the\nhappy idea was hit upon of having\none of them talk the marriage ser\nvice into the phonograph and with\nthe machine in his pocket the hap\npy bridegroom hastened to the\nhouse of his fiancee and there the\ntwo were joined in wedlock by the\nmetallic utterances of a swiftly re\nvolving cylinder\nIt can now be seen how useful the\nphonograph may become in this\nconnection No longer will it be\nnecessary for eloping couples ot\nthose who find it necessary to mar\nI\nry in a hurry to go chasing abour\nto pull a clergyman out of bed at\nunseemly hours of the night\nPhonograph cylinders charged\nwith the words necessary to the\nmarriage service can be placed on\nsale at the corner drug store and\nall that is needed is to purchase\none and set the instrument at work\nIf carried to a logical conclusion I\nthe marriage service by means of a\nphonograph can be sold with the\nmarriage license and matrimonial\nly inclined couples can have\ntheir weWdings as lavish or\nas private as their means or incli\nnations permit without having to\ntake a clergyman in to considera\ntion at all\nAs for the latter it opens up a\nnew Held of industry and one\nwhich should be profitable The\nminister can spend his leisure time\nin talking into phonographs and\nplace the cylinders on sale at the\nmost convenient points in the city\nHenderson Gleaner\nDR PINER I1V\nBad Boys Played a Mighty Good\nJoke On the Good flan\nRev VV K Finer pastor of the\nState Street Methodist Church was\nthis week the unconscious victim ol\ngod joke\nA number of youngsters had cap\ntured a pup The boys were about\nto fight over possession of the dog\nwhen one made the happy suggC\nbon that one who told the biggest\nlie should have the canine\nWhen things had reached such\namicable agreement Mr Piuur\ndrove up but the boys were still\nfussingHere\nHere here little onus ex\nclaimed the minister what is this\nall about\naboutWhy\nWhy said the youngster the\none who tells the biggest lie owns\nthis dog\nieIm ashamed to replies the good\nMethodist preacher When I was\na little boy I never told a lie\nOne boy in the crowd with wis\ndom far ahead of his years ap\nproached Mr Piner and holding\nout the dog said Here Mister\nHeres your pupBowling Green\nNews\nI Purchased 4250 For 7\nPeter Greenhalgh of Venango\nPa bought a small fortune for 7\nAfter the death of Joseph Blystone\na few weeks ago L S Sherred was\nappointed adminibtrator Green\nhalgh bicjjn the safe for 7 and had\nit carted home It had been drilled\nopen before the bale and nothing of\nvalue was discovered\nI think I made a bail bargain\nsaid Greenhalgli tb hhfwite This\nold safe aint Vorth 717\nHe examined it fuftherarid reach\ned his hand in between the parti\ntion He found gold and bank notes\namounting to 4250 Exchange\nHEADACHE =\nIloth mr wife and rarcelflmve been\npain OASOARJTS and tbey are the beet\nmedicine we have ever had in the bouae Last\nweek my wife was frantic with headache tor\ntwodayi aka tried some IrourCASOARETS\nand they relieved the pain In her bead almost\nImmediately We bosh neCaacarQta\nOKAS STXDIFOIID\nFHtsturir Site t DoposU Co PltUbur Pa\nCANDY\nCATHARTIC\nTRADt MAiM ftMWVMO\nPJoaeagt nolen\nQpoU tyTMBloktjn YOftkeq or GrlpolOo Mo lid\nv ti < <\ns A > f v v vv X v v\nSCRUPULOUS EDITORS\nAllow Little in Their Publications Ifea\nWill 01 < end Readers\nAn absurd story went the round\nof the press a couple of years ago\neaid a gentleman connected with the\nbusiness end of a prominent New\nYork publishing house U > the effect\nthat Hudyard Kipling had bit n com\npalled to cut out the word wint from\none of hit short tales Of course so\nfar as Kipling was concerned KochF\nyarn answered itself but if the au\nthor referred to had been almost any\nbody else it wouldnt have done to\ndismiss it with a shrug and a smile\nUnless you have had an opportunity\nto see something of a modern publish\ning house from behind the scenesr\ncontinued the speaker you have no\nidea of the scrupulous care that is i\ntaken nowadays to avoid offending\nthe great middle classes I am refer\nring particularly to houses that pub\nlish magazines and weeklies of the\nkind that make a bid for what we call k\na fireside circulation All such con\ncerns have a set of castiron rules in\nregard to topics that mayor may not\nbe mentioned in the columns of their\npublications and flippant refercnc i\nto religion is the thing they hold 4t\npecially in dread rrhatreminds 1I1\nby the way of rather an amusing li\ntie incident which occurred last sun\nrncr and illustrates this very point\nhad occasion to spend a week or so r\nChicago in June and before I startt < s\na friend who edits one of the popular\nmagazines which is making a date pr\nate struggle to get a foothold with tIt\npublic asked me to hunt up a well\nknown writer of that city and return\na manuscript for revision Idl him\nto eliminate all reference to rclipon\nin the dialogue said the editor and\nto substitute something anything\nhe pleases that couldnt hurt thet\nfeelings of some fanatic I delivered\nthe message and the Chicago genius\nwas highly indignant but before I\nleft ho concluded to sacrifice his art\nto considerations of filthy lucre and\nmnde the changes specified The\nstuff might not have offended any\nbody said my friend the editor when\nI made my report but it certainly\npoked fun at one of the greatest Prot\nestant denominations in the world\nand we make it a positive rule to print\nno refprrnopR to religion in fiction\nYou can never tell whore lH hart\ngetting on All the younger publica\ntions are equally timid in that respct\nIt is a curious fact in this same con\nnection that even the big general ad\nvertisers of the north always scru\ntinize their copy with the utmost\ncare to see that it contains nothing\nthat might possibly give offense to\neome devout and supersensitive read\ner For example a wellknown man\nufacturing concern which dots an im\nmense amount advertising got up a\nspecial design for a comic oaltrulariv <\nccmtly and after the larger part uft lr\norder had been printed and deliver u\none of the partners happened to not it n\nthat the expression Holy srm > la\nwas used in the text under out uf th\nhumorous picture He inimedinti us\ncountermanded the order taking the t m\nVWi\nposition that the phrase might possi\nbly give offense to some seriousmind\nedPQrson when something else would\ndo just as well mention this inci\ndent because it is a good illustration\nof the extraordinary pains that ate\ntaken in certain lines at present to\nkeep off of other folks cornHN 0\nTimesDemocrat\nLONG TIME UNDER WATER\nSailor Resuscitated After Being Twen\nty Minutes Without Air\nHow long can a human being exist\nwithout air Two or three minutes\nyou will say but then how can you ac\ncount for the resuBcrtation of persons\nwho have been much longer than that\nunder water A ailor on the Bel\ngenJund lying jn port at Philudel\nphia became ip anc anvil jumped over\nboard As he did not rise again it\nwas necessary to use grappling hook\nto recover his body and it was 20\nminutes before H > vas brought to tin\nsurface Everybody ihqluding a doc\ntor who hnd licjji summoned\nthought the man wn8dcnd but as the\nharbor policemen have instructions to\ntry to revive all drowned persons\nthey set to work with the usual meth\nods and after an hours hard labor\nthe man breathed and opened his\neyes Then he wAs taken to a hos\npital and the m3xt day was not only\nrestored to health but had also re\ncovered his reason Golden Days\nInsurance for Bathers\nInsurance r lathers iff the new\nest enterprise in the insurance line\nIn England Pennyinthoslot ma\nchines will be erected in popular\nx1thin lanes Before\nI\nk'
Um die Volltexte für alle Suchergebnisse auf der ersten Seite abzurufen und zu speichern, können wir eine for-Schleife entwerfen:
# Volltexte für die gesamte erste Seite der Suchergebnisse speichern
# items = search_results["items"]
# for item in items:
# ocr_text = item["ocr_eng"]
# title = item["title"]
# date = item["date"]
# with open(f"{title}_{date}.txt", "w", encoding="utf-8") as file:
# file.write(ocr_text)
Das wollen wir jetzt für alle Suchergebnisse auf allen Seiten reproduzieren.
8.3.3. Abfrage aller Volltexte mit “book review”#
Zunächst legen wir in unserem aktuellen Arbeitsverzeichnis (=Ordner, in dem die Jupyter Notebooks liegen) ein neues Verzeichnis an, in dem wir die Volltexte abspeichern werden:
# neues Verzeichnis anlegen: in diesem Ordner werden die Textdateien gespeichert
# if not os.path.exists("loc_ocr"):
# os.makedirs("loc_ocr")
# Arbeitsverzeichnis wechseln: Die Texte sollen im Verzeichnis "spokentext_corpus" gespeichert werden
# os.chdir(os.path.join(os.getcwd(), "loc_ocr"))
Wie gehen wir vor, um jetzt unsere for-Schleife oben nacheinander auf alle Ergebnisseiten anzuwenden? Eine Idee wäre die Verwendung einer while Schleife mit HTTP Antwort != 200 als break-Bedingung. Diese Strategie ist aber nur anwendbar, wenn beim Abruf einer ungültigen Seite eine HTTP-Antwort ungleich 200 zurückgegeben wird. Das müssen wir zunächst überprüfen: Was passiert, wenn eine nicht existierende Seite aufgerufen wird? Als Beispiel rufen wir die Seite https://chroniclingamerica.loc.gov/search/pages/results/?rows=20&format=json&sequence=0&phrasetext=book+review&andtext=&page=1640 auf.
Tatsächlich gibt es eine Umleitung auf Seite 1 mit einem gültigen HTTP-Statuscode. Wir können also in diesem Fall die Strategie mit der while-Schleife nicht verwenden.
Eine andere Idee ist die Verwendung einer for-Schleife. Dazu müssen wir aber die Gesamtzahl der Ergebnisseiten kennen. Die Gesamtzahl der Ergebnisseiten können wir aber einfach ermitteln:
# Gesamtanzahl der Ergebnisseiten ermitteln: Anzahl der Ergebnisse durch Anzahl der Ergebnisse pro Seite teilen
url = "https://chroniclingamerica.loc.gov/search/pages/results/?andtext=&phrasetext=book+review&format=json"
search_results = requests.get(url).json()
pages_float = search_results["totalItems"] / search_results["itemsPerPage"]
pages = math.ceil(pages_float)+1 # aufrunden und 1 addieren
pages
1709
Zu der Gesamtzahl der Seiten addieren wir 1, da wir später die range(1, n)-Funktion verwenden wollen, welche eine Integersequenz von Zahl 1 bis Zahl n-1 generiert.
Unsere for-Schleife sieht dann so aus:
# Volltexte zu allen Ergebnissen von allen Ergebnisseiten speichern
# url = "https://chroniclingamerica.loc.gov/search/pages/results/?andtext=&phrasetext=book+review&format=json&page="
# for page in range(1, pages):
# request_url = url + str(page)
# response = requests.get(request_url).json()
# # for-Schleife für eine einzelne Ergebnisseite einsetzen
# items = response["items"]
# for item in items:
# ocr_text = item["ocr_eng"]
# title = item["title"]
# date = item["date"]
# with open(f"{title}_{date}.txt", "w", encoding="utf-8") as file:
# file.write(ocr_text)
Aber Achtung! Beim Ausführen des Codes oben gibt es nach einigen Schleifendurchläufen eine Fehlermeldung: JSONDecodeError: Expecting value: line 1 column 1 (char 0). Die Fehlermeldung entsteht dann, wenn die HTTP-Anfrage keine erfolgreiche Antwort liefert. Das liegt mit großer Wahrscheinlichkeit daran, dass wir uns nicht an die Einschränkungen der LOC gehalten haben und die HTTP-Anfrage dadurch ab einem bestimmten Punkt abgelehnt wird. Wenn wir dann versuchen, den Antwortbody mithilfe der .json()-Methode in ein Python Dictionary umzuwandeln, teilt der Python interpreter uns mit, dass das nicht möglich ist, weil wir die Methode nicht auf einen gültigen JSON-String angewendet haben.
Bei der Abfrage von sehr vielen Seiten müssen wir uns also nach den Einschränkungen der LOC richten. Die LOC hat Einschränkungen für die der Chronicling America API übergeordnete Seite loc.gov festgelegt, und wir können vermuten, dass die Einschränkungen auch für die Chronicling America API gelten: https://www.loc.gov/apis/json-and-yaml/working-within-limits
Um auf der sicheren Seite zu sein, richten wir uns nach der restriktivsten Vorgabe, nach der nur 20 Abfragen alle 10 Sekunden erlaubt sind.
Wie können wir also die HTTP-Abfragen auf 20 Abfragen je 10 Sekunden einschränken? Was wir brauchen nennt sich “rate limiting”, also eine Begrenzung der Abfragerate, die wir in unseren Code einbauen müssen.
Um die Abfragerate einzuschränken, gibt es zwei etablierte Möglichkeiten:
Funktion
time.sleep()aus dem Paket time. Die Funktion time.sleep(x) kann in den Schleifenkörper einer for-Schleife eingefügt werden, um den nächsten Schleifendurchlauf um x Sekunden zu verzögern. Diese Methode ist einstiegsfreundlich, aber ungenau, weil die Laufzeit der Schleife selbst nicht in die Wartezeit mit einbezogen wird, sodass der nächste Schleifendurchlauf länger als notwendig verzögert wird.Python Dekoratoren aus dem Paket ratelimit. Wesentlich effizienter und eleganter ist die Verwendung von sogenannten Python Dekoratoren bzw. Decorators. Das Paket ratelimit bietet zwei solche Dekoratoren, die dazu verwendet werden können, um zu registrieren, wie häufig eine Funktion nacheinander aufgerufen wird, und die ab einer bestimmten Anzahl wiederholter Aufrufe eine Wartepause erzwingen. Um Decorators verwenden zu können, müssen wir unsere Abfrage jedoch in eine Funktion verpacken.
Note
Python Dekoratoren (Decorators)
A decorator in Python is a function that accepts another function as an argument. The decorator will usually modify or enhance the function it accepted and return the modified function. This means that when you call a decorated function, you will get a function that may be a little different that may have additional features compared with the base definition.
Quelle: Michael Droscill (2017).
Dekoratoren beruhen auf einem komplexen Konzept und wir können hier nicht tiefer einsteigen, aber wenn die ein oder andere Person doch etwas tiefer einsteigen will, kann ich diese beiden Ressourcen empfehlen:
Primer on Python Decorators, https://realpython.com/primer-on-python-decorators/
Python Decorators in 15 Minutes, https://www.youtube.com/watch?v=r7Dtus7N4pI
Bei der Verwendung der Dekoratoren aus dem Paket ratelimit verwenden wir diese Anleitung von Akshay Ranganath:
Rate Limiting with Python, https://akshayranganath.github.io/Rate-Limiting-With-Python/
# 1) Rate limiting mit time.sleep()
# url = "https://chroniclingamerica.loc.gov/search/pages/results/?andtext=&phrasetext=book+review&format=json"
# search_results = requests.get(url).json()
# pages_float = search_results["totalItems"] / search_results["itemsPerPage"]
# pages = math.ceil(pages_float) # aufrunden
# url = "https://chroniclingamerica.loc.gov/search/pages/results/?andtext=&phrasetext=book+review&format=json&page="
# for page in range(1, pages):
# request_url = url + str(page)
# response = requests.get(request_url).json()
# # for-Schleife für eine einzelne Ergebnisseite einsetzen
# items = response["items"]
# for item in items:
# ocr_text = item["ocr_eng"]
# title = item["title"]
# date = item["date"]
# with open(f"{title}_{date}.txt", "w", encoding="utf-8") as file:
# file.write(ocr_text)
# time.sleep(10)
# 2) Rate limiting mit Python decorators
# url = "https://chroniclingamerica.loc.gov/search/pages/results/?andtext=&phrasetext=book+review&format=json"
# search_results = requests.get(url).json()
# pages_float = search_results["totalItems"] / search_results["itemsPerPage"]
# pages = math.ceil(pages_float) # aufrunden
# url = url + "&page="
# TEN_SECONDS = 10
# CALLS_PER_TEN_SECONDS = 20 # 20 Abfragen in 10 Sekunden
# @sleep_and_retry
# @limits(calls=CALLS_PER_TEN_SECONDS, period=TEN_SECONDS)
# def get_fulltext(url):
# response = requests.get(url).json()
# # for-Schleife für eine einzelne Ergebnisseite einsetzen
# items = response["items"]
# for item in items:
# ocr_text = item["ocr_eng"]
# title = item["title"]
# date = item["date"]
# with open(f"{title}_{date}.txt", "w", encoding="utf-8") as file:
# file.write(ocr_text)
# for page in range(1, pages):
# request_url = url + str(page)
# get_fulltext(request_url)
Note
Konstanten (Constants)
Im Code oben verwenden wir Großbuchstaben, um die beiden Variablen CALLS_PER_TEN_SECONDS und TEN_SECONDS zu benennen. Diese Schreibweise hat sich in Python für Konstanten etabliert, also für Variablen, deren Wert sich im Programmverlauf nicht ändert.
8.3.4. Quellen#
Michael Driscoll. Chapter 25 – Decorators. 2017. URL: https://python101.pythonlibrary.org/chapter25_decorators.html.
Akshay Ranganath. Rate Limiting with Python. 2021. URL: https://akshayranganath.github.io/Rate-Limiting-With-Python/.
Guido van Rossum, Barry Warsaw, and Nick Coghlan. PEP 8: Constants. 2013. URL: https://peps.python.org/pep-0008/#constants.
Geir Arne Hjelle. Primer on Python Decorators. 2023. URL: https://realpython.com/primer-on-python-decorators/.
Kite. Python Decorators in 15 Minutes. 2020. URL: https://www.youtube.com/watch?v=r7Dtus7N4pI.
Leodanis Pozo Ramos. Python Constants: Improve Your Code's Maintainability. 2022. URL: https://realpython.com/python-constants/.
Library of Congress. Chronicling America. About the Site and API. 2023. URL: https://chroniclingamerica.loc.gov/about/api/.
Library of Congress. Working Within Limits. 2023. URL: https://www.loc.gov/apis/json-and-yaml/working-within-limits.