10.1. Selenium ist kein Hammer#
Bei der Entscheidung für die richtige Webscraping-Strategie lohnt es sich, das folgende Zitat im Hinterkopf zu behalten:

Fig. 10.1 Selenium ist kein Hammer. Quelle: https://alvistor.com/maslows-hammer-the-all-in-one-productivity-tool/#
Im Abschnitt “Statisch vs. Dynamisch?” habt ihr bereits gesehen, dass es viele verschiedene Rendering-Verfahren gibt. Ihr habt außerdem am Beispiel von readthedocs.org und projekt-gutenberg.org gesehen, dass serverseitig dynamisch generierte Inhalte manchmal direkt mithilfe einer API abgefragt werden können, ohne, dass überhaupt BeautifulSoup oder Selenium zum Einsatz kommen müssen: Im Fall von readthedocs.org konnte die URL, die bei der manuellen Verwendung der Suchmaske im Browserfenster angezeigt wird, direkt für eine HTTP GET-Anfrage verwendet werden. Im Fall von projekt-gutenberg.org musste die Abfrage dagegen über ein php-Formular mithilfe der HTTP POST-Methode gestellt werden.
Eine sehr ähliche Strategie kann auch zur Simulierung der Suche auf manchen clientseitig implementierten Suchseiten angewandt werden. In dem Fall unterscheidet sich die Abfrage-URL allerdings von der URL, die im Browserfenster angezeigt wird. Denn wie wir bereits im Abschnitt “Statisch vs. Dynamisch” besprochen haben, wird bei clientseitigen Renderingverfahren zunächst eine noch “unfertige” HTML-Seite geladen, und erst dann wird mithilfe von JavaScript über eine Web-API die restlichen Inhalte abgefragt und in das HTML-Gerüst eingefügt. Eine sehr weit verbreitete Web-API, die zur nachträglichen Abfrage von Ressourcen verwendet wird, heißt Fetch (und das ältere XMLHttpRequest, kurz XHR). Solche API-Abfragen können über den Netzwerke-Tab in den Browser-Entwicklertools eingesehen werden. Als Beispiel betrachten wir die Suche über tagesschau.de. Beim Eingeben eines Suchbegriffs wird eine URL erzeugt, die ganz ähnlich aussieht wie im Beispiel readthedocs.org: https://www.tagesschau.de/suche#/all/1/?searchText=klimawandel. Wenn wir allerdings eine GET-Anfrage für diese URL stellen, dann bekommen wir nur das HTML-Gerüst der Seite ohne die Suchergebnisse zurück: Denn die Suche ist clientseitig implementiert, sodass die Inhalte bei deaktiviertem JavaScript gar nicht geladen werden. Die Suchergebnisse werden nämlich beim Eingeben eines Suchbegriffs über die bereits erwähnte Schnittstelle XHR angefragt und in das HTML-Gerüst eingefügt, ohne, dass die Seite dabei neu geladen werden muss. Das lässt sich leicht mit einem Blick auf die Anfragen unter Netzwerk -> Fetch/XHR ermitteln:
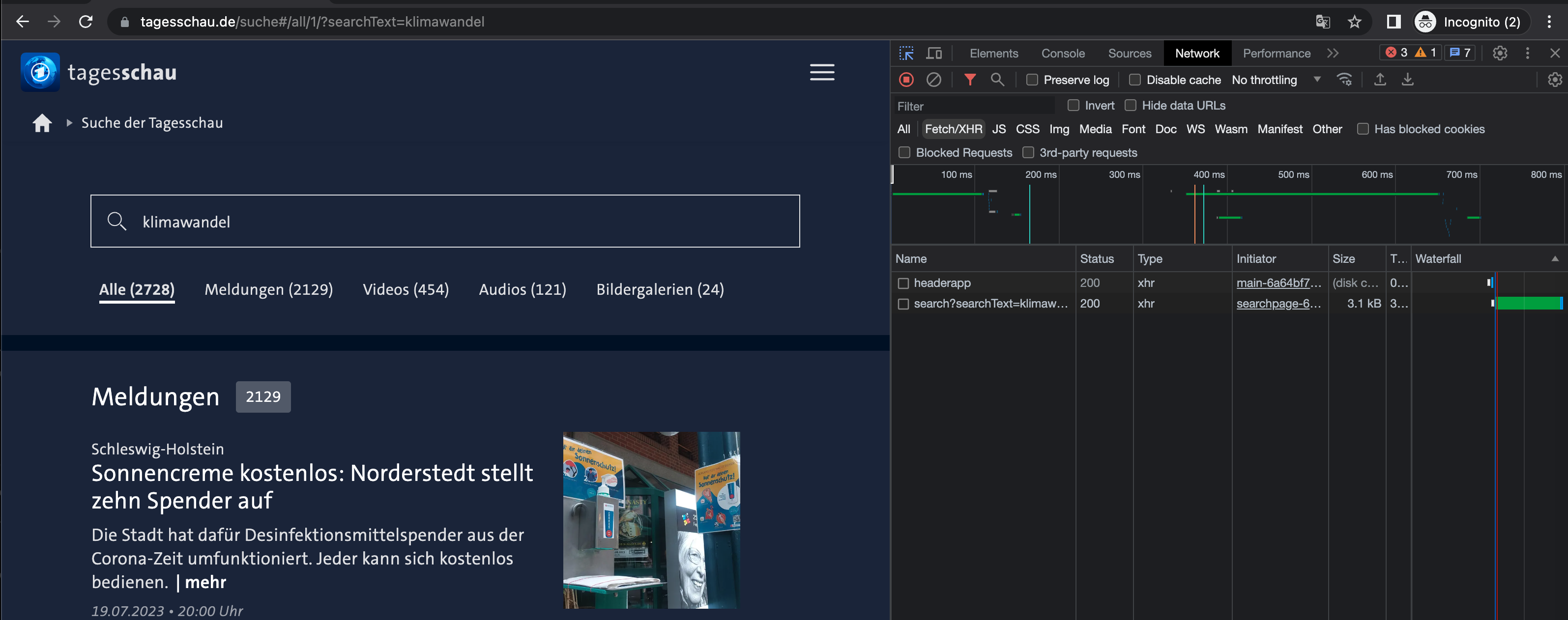
Fig. 10.2 Ansicht der Fetch/XHR-Anfragen in den Browser-Entwicklertools.#
Die gesuchte Anfrage hat den Namen search?searchText=klimawandel. Durch Mausklick auf den Namen der Anfrage öffnen sich weitere Informationen zu der gestellten Anfrage. Unter “Initiator” können wir beispielsweise nachlesen, welche JavaScript-Datei die XHR-Anfrage veranlasst hat. Diese Information ist für uns allerdings nicht weiter wichtig. Um die XHR-Anfrage zu simulieren, müssen wir nur die Abfrage-URL ermitteln, und die Abfrage-URL findet sich unter “Headers”:
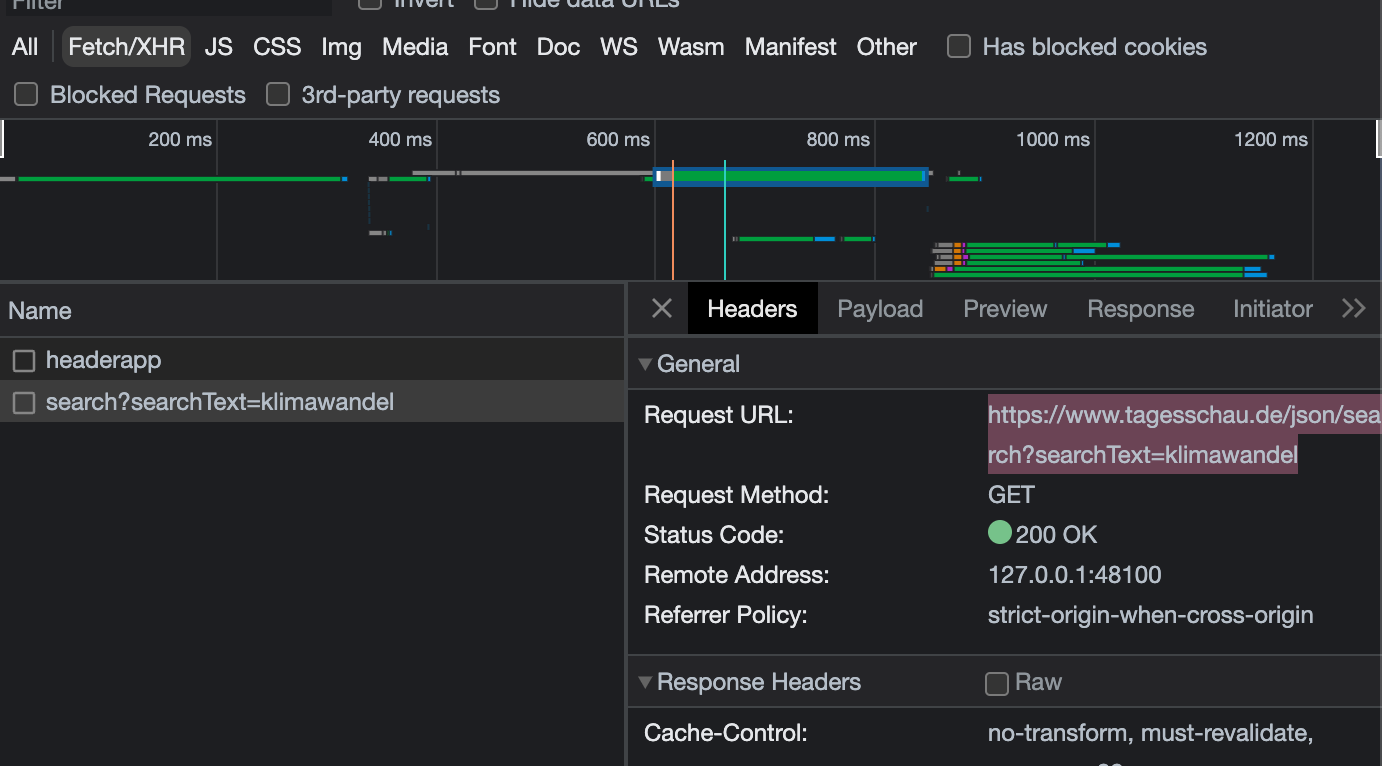
Fig. 10.3 Ermittlung des Abfrage-URL für die XHR-Anfrage#
Mit dieser URL können wir eine ganz simple HTTP GET-Anfrage stellen. Da die Ergebnisse im JSON-Format zurückgegeben werden, können wir die Suchergebnisse als Python Dictionary darstellen:
import requests
page = requests.get("https://www.tagesschau.de/json/search?searchText=klimawandel")
# page.json()
Um diese Abfrage für alle Ergebnisseiten zu wiederholen, können wir uns die Abfrage-URLs für verschiedene Ergebnisseiten ansehen. Für Seite 4 ist die Abfrage-URL beispielsweise “https://www.tagesschau.de/json/search?searchText=klimawandel&documentType=article&pageIndex=3”. Aus dem Vergleich der Abfrage-URLs können wir schließen: Die Abfrage-URLs für die Ergebnisseiten unterscheiden sich nur im Parameter pageIndex, der Werte in der Spanne von 0 bis 70 für alle 71 Ergebnisseiten annimmt. Mit dieser Information könnten wir jetzt zum Beispiel eine for-Schleife schreiben, welche eine Abfrage für jede der 71 Ergebnisseiten stellt.
XHR und Fetch werden aber nicht nur zur Abfrage von Suchergebnissen angewandt, sondern ganz allgemein für JavaScript-Anwendungen, die auf irgendwelche Ressourcen auf dem Server zurückgreifen. Ein Beispiel sind die Daten zu Gartenvögeln, welche der NABU auf seiner Website in einer interaktiven Karte visualisiert: https://www.nabu.de/tiere-und-pflanzen/aktionen-und-projekte/stunde-der-gartenvoegel/ergebnisse/15767.html. Hier werden die Daten ebenfalls über eine Fetch/XHR-API abgefragt: Die Daten zur Verbreitung der Gartenvögel werden aus zwei CSV-Dateien entnommen, sdg_vogelarteninfo.csv und sdg_2023.csv. Die beiden CSV-Dateien können in diesem Fall sogar ganz ohne Python durch Doppelklick auf die Tabellen heruntergeladen werden.
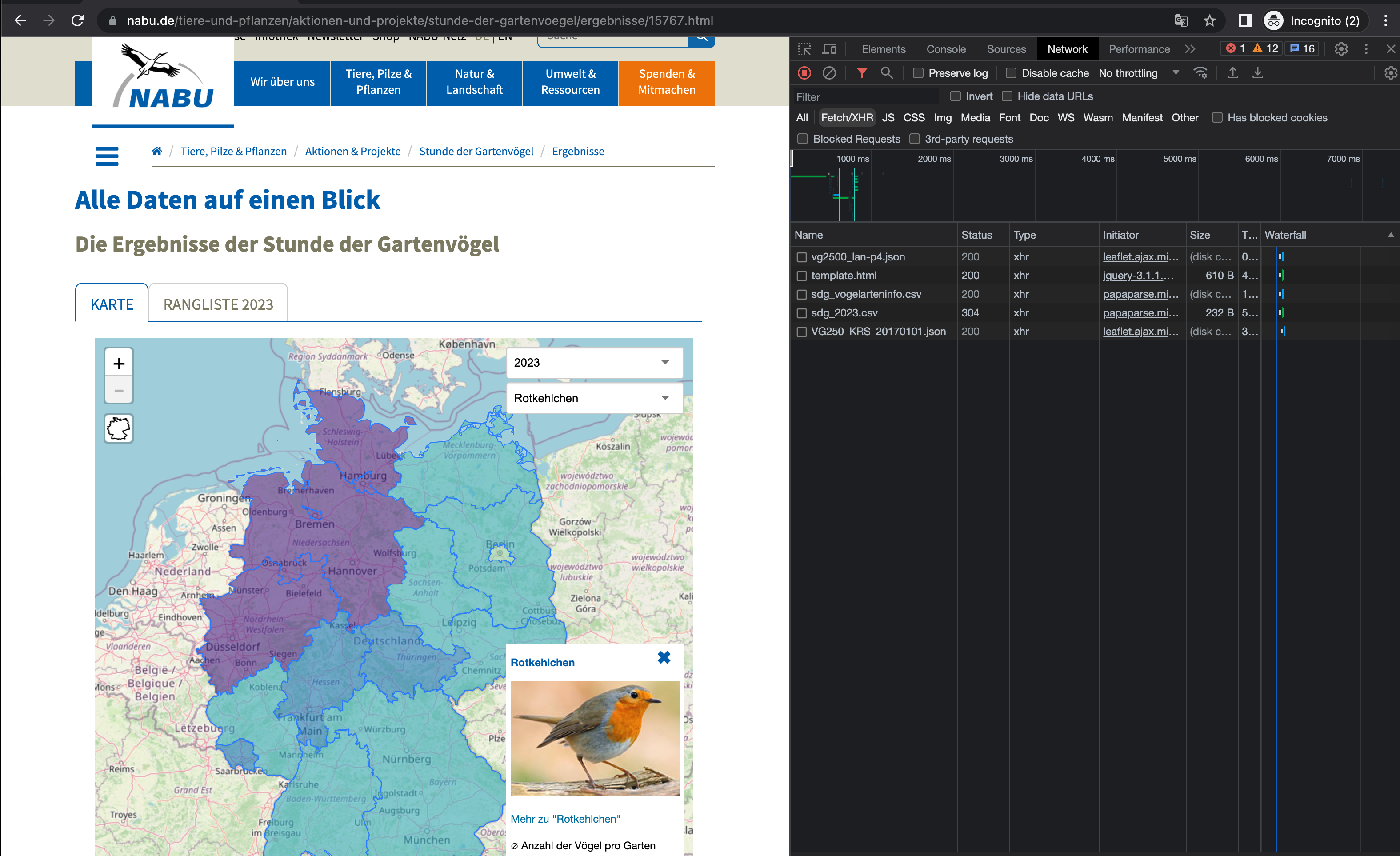
Fig. 10.4 XHR-Anfragen zur Abfrage von Daten für die Gartenvogel-Karte.#
Warning
Das hier vorgeschlagene Vorgehen solltet ihr nicht pauschal anwenden, sondern ihr solltet ganz genau schauen, welche Daten ihr dadurch abfragt und wie ihr dabei vorgeht. Denn in Deutschland gelten seit 2007 die sogenannten “Hacker-Paragrafen”, die das Abfangen und Ausspähen von Daten aus einer nichtöffentlichen Datenübermittlung unter Strafe stellen. Diese Paragrafen sind recht vage formuliert, insbesondere kann die Frage, wann eine Datenübermittlung “nichtöffentlich” ist, nach der Einschätzung von Rechtsanwältin Ines Hassemer “im Einzelfall kaum ohne IT-Spezifisches Fachwissen geklärt werden” (Hassemer 2019, S. 2678) und “wird auch in der Literatur kontrovers diskutiert.” (Hassemer 2019, S. 2676). Die Rechtsanwältin kommt deswegen zu der Einschätzung: “Aus strafrechtlicher Sicht lässt sich der Begriff kaum noch mit dem strafrechtlichen Bestimmtheitsgebot in Einklang bringen.” (Hassemer 2019, S. 2678).
Wenn ihr den Netzwerkinspektor zur Extraktion von Daten nutzen wollt, befindet ihr euch also unter Umständen in einem rechtlichen Graubereich und ihr solltet unbedingt sichergehen, dass ihr dabei keinerlei technische Schranken umgeht, und, dass ihr wirklich nur die Daten abfragt, die auch genau so öffentlich auf der Webseite stehen. Mehr zur rechtlichen Einschätzung hier und hier.
10.1.1. Quellen#
Ines M. Hassemer. § 43 Strafrecht im Bereich der Informationstechnologien (Teil 1). In Astrid Auer-Reinsdorff and Isabell Conrad, editors, Handbuch des IT- und Datenschutzrechts, pages 2652–2726. C.H. Beck, 2019. URL: https://fu-berlin.primo.exlibrisgroup.com/permalink/49KOBV_FUB/1v1tp5h/alma9959133505402883.
Vrijraj Singh. Fetch API: A Modern Replacement for XMLHttpRequest. 2019. URL: https://medium.com/codingurukul/fetch-api-a-modern-replacement-for-xmlhttprequest-c24ced9ff8d3.
MDN Contributors. Fetch API. 2023. URL: https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API.
MDN Contributors. XMLHttpRequest. 2023. URL: https://developer.mozilla.org/en-US/docs/Web/API/XMLHttpRequest.